Объемная цифра 8 для праздников и фотосессий. Часть вторая. Украшаем в виде единорожки. | Радость Творчества
Всех приветствую!
Недавно я начала делать объемную цифру «8» и рассказала подробно как можно сделать основу из картона. Если вам интересна эта публикация, то ссылку на нее я оставлю в конце этой статьи.
Сегодня я расскажу как оформила свою восьмерку и что получилось в итоге.
С дочкой мы обговаривали несколько вариантов цифры и она выбрала цифру — единорожку. Поэтому наша объемная цифра будет украшена в виде единорога из мультфильма.
Основу я обклеила гофрированной бумагой белого цвета.
объемная цифра, цифра 8 своими рукамиобъемная цифра, цифра 8 своими руками
Сначала приклеиваю одну сторону восьмерки на гофрированную бумагу. Я пользуюсь горячим клеем, потому что так удобнее и быстрее. Постепенно промазываю края заготовки, затем прикладываю гофрированную бумагу.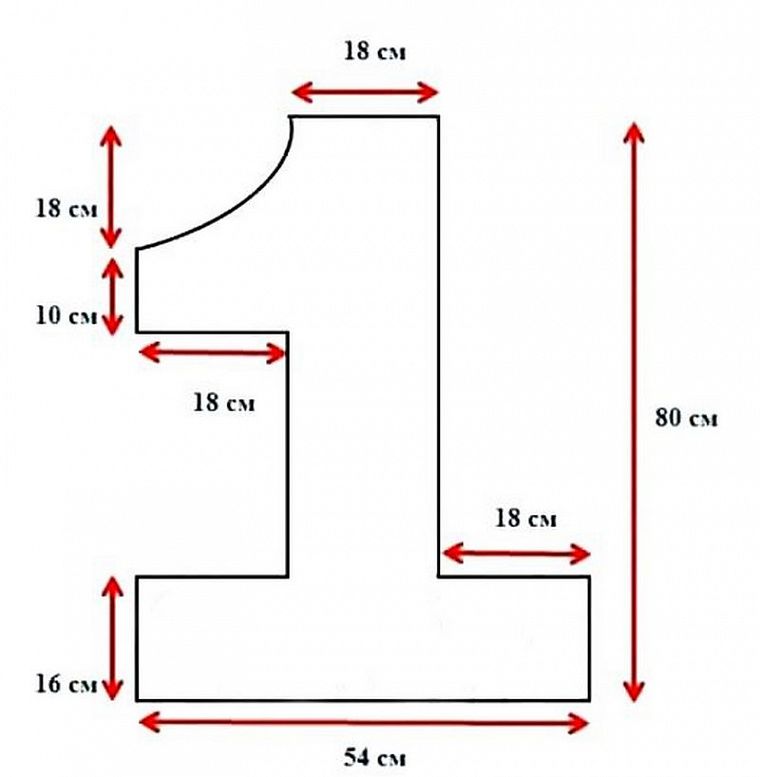
объемная цифра 8 своими руками.
цифра 8 для праздников и фотосессий своими руками пошаговоцифра 8 для праздников и фотосессий своими руками пошагово
Затем аккуратно вырезаю по контуру, оставляя 1-2 мм в запасе. Таким же образом приклеиваю вторую сторону и вырезаю.
объемная цифра 8 , мастер класс, фотообъемная цифра 8 , мастер класс, фото
Осталось закрыть боковые стороны заготовки. Для этого отрезаем полосу из гофрированной бумаги шириной 8,5 сантиметров. Можно нарезать несколько полос для удобства и приклеить их встык.
объемная цифра из картона сделать пошаговообъемная цифра из картона сделать пошагово
Постепенно приклеиваем бумагу со всех сторон, тщательно промазывая края.
объемная цифра 8 своими руками пошагово фотообъемная цифра 8 своими руками пошагово фото
Не забываем проклеить внутренние круги восьмерки.
цифра 8 своими руками мастер классцифра 8 своими руками мастер класс
Основа для украшения готова. Теперь изготовим элементы украшения единорога.
Теперь изготовим элементы украшения единорога.
Ушки я нарисовала на плотном картоне и обклеила блестящей самоклеющейся бумагой из магазина фикс прайс. Вот мой шаблон:
единорог ушки шаблон фотоединорог ушки шаблон фото
А вот готовые ушки:
уши единорога как сделать фотоуши единорога как сделать фото
Рог сделала из плотного картона. Сначала вырезала конус из формата А4 с круглым основанием.
как сделать рог единорога из картона пошагово фотокак сделать рог единорога из картона пошагово фото
Затем свернула его и приклеила.
рог единорога из картона сделать своими руками фоторог единорога из картона сделать своими руками фото
рог единорога своими руками пошагово фоторог единорога своими руками пошагово фото
Обклеила готовый рог самоклеющейся золотой бумагой и добавила узкую ленточку ярко-розового цвета.
цифра единорожка сделать пошагово фото мастер классцифра единорожка сделать пошагово фото мастер класс
Приклеила на верхнюю часть цифры рог и уши единорожки.:max_bytes(150000):strip_icc()/NUMBERS-01-56a80f0c5f9b58b7d0f045d3.png)
цифра 8 единорожка своими руками пошагово фото
Для изготовления гривы использовала разноцветную гофрированную бумагу которая нашлась дома.
гофрированная бумага поделки фотогофрированная бумага поделки фото
Нарезала полоски примерно 2 см шириной и длиной 40-45 см.
как сделать гриву единорожке из бумаги пошагово фотокак сделать гриву единорожке из бумаги пошагово фото
Слегка вытянула их по длине и закрутила края на палец, чтобы сформировать локоны. Приклеила горячим клеем располагая полоски в произвольном порядке.
Полоски укладывала примерно как на фото, чтобы грива спускалась немного назад, а не прямо.
как сделать цифру единорожку своими руками фотокак сделать цифру единорожку своими руками фото
Из этих же полосок гофрированной бумаги сформировала цветочки. Сначала скручивала и подклевала серединку.
Затем перекручивала бумагу и формировала лепестки.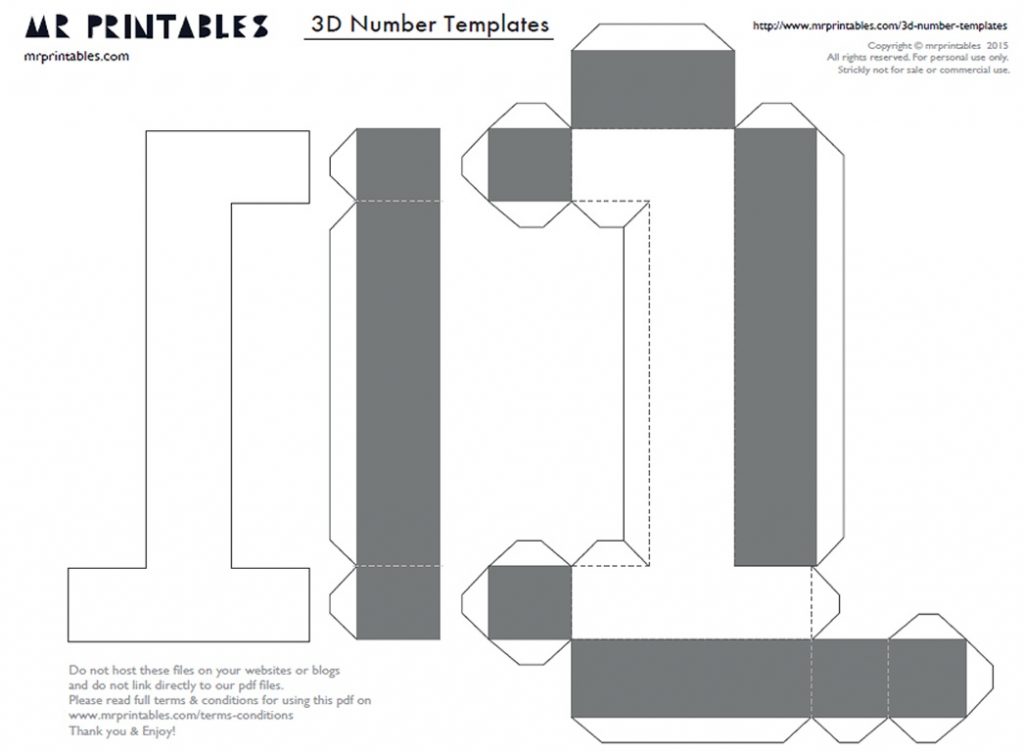 Каждый лепесток подклеивала капелькой клея. Такие цветы я придумала по ходу работы сама, раньше нигде такие не видела.
Каждый лепесток подклеивала капелькой клея. Такие цветы я придумала по ходу работы сама, раньше нигде такие не видела.
гофрированная бумага, цветы простые, фото
Цветочки приклеила вокруг рога.
цифра единорожка пошагово фотоцифра единорожка пошагово фото
Добавила еще несколько цветочков в центр гривы.
объемная цифра единорожка на детский день рождения фото пошаговообъемная цифра единорожка на детский день рождения фото пошагово
Глазки и рот нарисовала на глянцевой цветной бумаге и приклеила по бокам. Также вырезала несколько блестящих разноцветных звездочек из самоклеющейся цветной бумаги.
цифра 8 единорожка мастер класс своими руками фотоцифра 8 единорожка мастер класс своими руками фото
Получилась цифра очень похожая на первоначальную задумку в виде Единорога из мультфильма.
Меня смущал только неаккуратный край внутренних кругов на основе и я решила его обклеить узкой тесьмой розового цвета.
Это был последний шаг в изготовлении цифры «8» для дня рождения моей дочки. Итог моей работы вы увидите на следующем фото.
Надеюсь мой опыт и идея оформления объемной цифры кому-то пригодится.
Если понравилась публикация — ставьте Лайк. Если вам интересно творчество в целом, а также оригинальные идеи и мастер классы — подписывайтесь на мой канал и делитесь с друзьями в соцсетях.
Спасибо за внимание!
Возможно вам будет интересно:
Объемная цифра 8 для праздников и фотосессий. Часть 1. Делаем основу
Как украсить объемные цифры для фотосессий и праздников. Примеры из личного опыта
Украшаем комнату бабочками из бумаги на детский день рождения
Корона диадема из фоамирана для девочки. Шаблоны и видео мастер класс
Мужской букет своими руками с колбасой и коньяком. Пошаговый мастер класс с фото
Пошаговый мастер класс с фото
делаем вместе. Лучшие идеи с подробным описанием
Цифра из гофрированной бумаги станет прекрасным и оригинальным украшением, если вы готовитесь к празднику или хотите устроить сюрприз для близкого человека. Объемный яркие циферки вам пригодятся не только на День рождения, но на юбилей свадьбы и даже на Новый год. Своими руками вы можете оформить самую запоминающуюся вечеринку для ваших друзей, а все, что для этого надо – разноцветные листы гофробумаги, купить которую можно в любом магазине с товарами для творчества или канцтоварах.
Цифра на годик из гофрированной бумаги
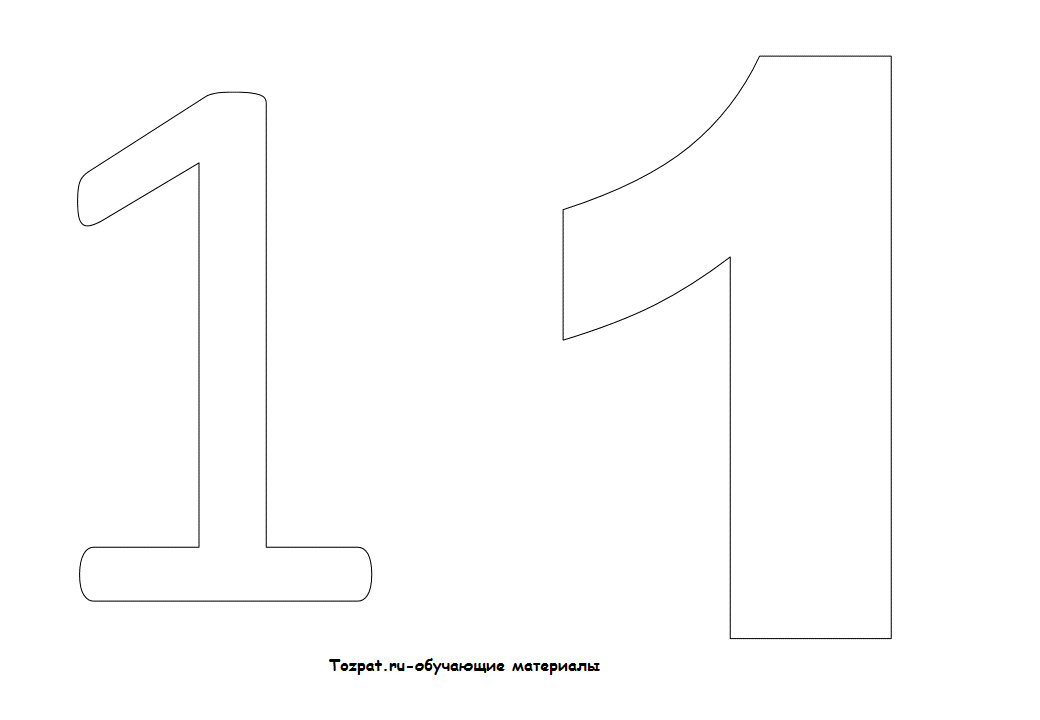
Цифра 1 из гофрированной бумаги станет украшением вашего праздника, а еще станет отличным фоном для семейных фотографий, которые сохранят память об этом дне надолго. Кусочки гофры подойдут, чтобы украсить картонную заготовку, а готовую поделку можно прикрепить к стене.
В данном случае мы будем делать плоскую поделку, поэтому понадобится плотный картон, к примеру, можно взять старую коробку от бытовой техники, нарисовать на листе контур единицы и аккуратно вырезать его.
Единицу нарисовать очень просто, используя карандаш и линейку, но если вы сомневаетесь, то можно использовать шаблон, который надо распечатать и приклеить на картон, а после – вырезать острыми ножницами.
Для поделки можно использовать гофру одного цвета или нескольких, тогда и фигура получится яркой. Обычно выбирают такой цвет, чтобы он сочетался с декором праздника, а может даже с нарядом именинника.
В данном случае для выполнения цифры из гофрированной бумаги своими руками мы будем использовать технику торцевания, поэтому нам необходимо гофру нарезать на небольшие квадраты. Размер квадрата будет зависеть от того, насколько «пушистым» вы хотите сделать главное украшение праздника. Например, у нас будет квадрат со стороной 5 см. Для начала лучше нарезать листы на полосы, затем сложить их вместе и нарезать квадратами.
Для удобства клей ПВА необходимо налить в блюдце, и взять карандаш для работы, мы будем использовать тупой конец карандаша. Предварительно саму картонную основу можно также обклеить полосками гофры.
Предварительно саму картонную основу можно также обклеить полосками гофры.
Теперь можно приступать к декорированию, в данном случае приклеивать бумажные квадратики мы будем только с одной стороны, но в случае с объемной цифрой декорировать также следует и боковые планки. Торцевание предполагает приклеивание к основе только середины каждого квадрата. Элементы приклеиваются близко друг к другу, поэтому и получается пушистое декорирование.
Тупой конец карандаша мы прикладываем к середине бумажного квадрата, а концы обкручиваем вокруг карандаша, так приклеивать центр к основе будет удобнее. После следует обмакнуть центр листика в клей и приставить его к основе. Придерживать надо несколько секунд, чтобы клей зафиксировался, после карандаш можно аккуратно убрать, и таким же образом приклеить следующий квадратик, как можно ближе к предыдущему, чтобы кончики квадратов торчали вверх.
Постепенно надо задекорировать всю поверхность картонного шаблона. Если вы хотите подвесить готовое украшение к стене, то сверху надо приделать петельку. А чтобы поставить ее на пол, сзади необходимо сделать подставку, чтобы поделка была устойчивой.
А чтобы поставить ее на пол, сзади необходимо сделать подставку, чтобы поделка была устойчивой.
Цифра 1 из гофрированной бумаги
Плоская цифра на годик из гофрированной бумаги в технике торцевание получается пушистой, но есть и другой способ украсить ее. Опять же вначале нам необходимо вырезать картонный шаблон. Использовать можно несколько слоев картона, чтобы шаблон получился достаточно плотным и не сгибался.
В Мексике практически на всех детских праздниках присутствует пиньята, это объемная игрушка, выполненная с картона и украшенная бумажными полосочками. В такой же технике будет украшена и наша цифра 1 из гофрированной бумаги своими руками.
По сравнению с торцеванием, украшение бумажными полосочками выполняется быстрее. Когда мы вырежем шаблон, его надо обклеить полосами гофры. Желательно использовать бумагу разных цветов, чтобы поделка получилась яркой.
Сначала листы гофры необходимо нарезать на полосы шириною около 5 см, а затем каждую полоску надрезать перпендикулярно, чтобы получилась «травка». Когда вы будете декорировать шаблон, начинать необходимо с нижней части. Клеем надо смазать только ту часть бумажной полоски, которая не надрезана «травкой». Каждую следующую полосу надо приклеивать так, чтобы бахрома скрывала приклеенную часть предыдущей полосочки.
Когда вы будете декорировать шаблон, начинать необходимо с нижней части. Клеем надо смазать только ту часть бумажной полоски, которая не надрезана «травкой». Каждую следующую полосу надо приклеивать так, чтобы бахрома скрывала приклеенную часть предыдущей полосочки.
Таким образом, обклеивается вся поверхность шаблона, а когда клей высохнет, можно оформлять праздник для вашего малыша. А если вы отправляетесь на первый День рождения к крестнице, то подготовьте такой подарок своими руками из бумаги.
Объемная цифра из гофрированной бумаги
А если вы знаете, как делать розы своими руками, то для вас будет не проблемой украсить своими руками и неповторимый детский праздник. Объемная цифра из гофрированная бумаги требует предварительной подготовки шаблона, ведь нам надо сделать объемную заготовку, которая, к тому же, должна быть и достаточно прочной.
Самый простой вариант – выполнить заготовку, используя картон, в данном случае пригодиться большая картонная коробка от бытовой техники. Если же под рукой у вас нет такой коробку, обратитесь за помощью в ближайший магазин продуктов или супермаркет, продавцы наверняка не откажут вам в помощи и отдадут со склада одну коробку. Ее надо будет разобрать на плоские листы: боковые широкие стороны пойдут на шаблоны цифр, а боковые планки можно вырезать с оставшегося картона.
Если же под рукой у вас нет такой коробку, обратитесь за помощью в ближайший магазин продуктов или супермаркет, продавцы наверняка не откажут вам в помощи и отдадут со склада одну коробку. Ее надо будет разобрать на плоские листы: боковые широкие стороны пойдут на шаблоны цифр, а боковые планки можно вырезать с оставшегося картона.
Чтобы сформировать основу вам также понадобится бумажный скотч, ведь только на бумажный скотч затем вы сможете приклеивать гофрированные цветочки.
Вам необходимо вырезать две одинаковые заготовки-цифры и широкие полосы, которыми мы оформим боковые планки объемной фигуры. Бумажный скотч вам поможет сформировать объемную заготовку, им следует аккуратно склеить швы, а для большей прочности можно обклеить скотчем по кругу.
Таким способом можно сделать любую цифру, а для ее украшения использовать пушистые бумажные помпоны или цветы из гофрированной бумаги своими руками.
Кроме того, заготовку можно выполнить из пенопласта, особенно, если вы недавно покупали крупную бытовую технику, и у вас остался пенопласт от упаковки. Такая основа получится достаточно прочной. Когда готова основа, можно приступать к творческому процессу,
Такая основа получится достаточно прочной. Когда готова основа, можно приступать к творческому процессу,
Цифра из гофрированной бумаги
Цифра на День рождения из гофрированной бумаги или салфеток получится пушистой, яркой, объемной. Такое украшение станет центром всего праздника, а еще помещение можно украсить объемными помпонами, воздушными шарами. Кроме цифр можно сделать украшения в виде большого шара, который также оформляется маленькими гофрированными цветочками. Как видите, такой простой материал как гофра дает огромный простор для творчества, в частности, поможет вам украсить дом к празднику, ведь День рождения вашего ребенка должно пройти незабываемо. А если вы отправляетесь на праздник к подруге, подготовьте для нее конфетный букет из тюльпанов.
Цифры из цветов гофрированной бумаги иногда используются и для оформления праздников для взрослых, конечно, не стоит напоминать имениннице о ее возрасте, но в годовщину свадьбы ваших родителей вы можете устроить им настоящий сюрприз.
Маленькие цветочки помогут вам задекорировать объемную заготовку. Есть несколько возможных вариантов, как сделать просто такие цветочки, не беспокойтесь, даже новичок справиться с этой работой.
Объемная основа должна быть плотно заполнена миниатюрными цветочками, чтобы через них не просматривалась картонная заготовка, поэтому существует два правила декорирования. Во-первых, цветочки должны быть пушистыми и объемными, а, во-вторых, приклеивать их следует близко друг к другу. Чтобы быть уверенной, что поделка получиться красивой, можно предварительно обклеить саму картонную заготовку бумагой в тон цветочкам.
Первым делом мы рассмотрим самый простой вариант, как сделать пушистый цветочек для украшения картонной заготовки. Для этого нам понадобиться, конечно, главный материал – гофра, а также дополнительные инструменты – ножницы и степлер.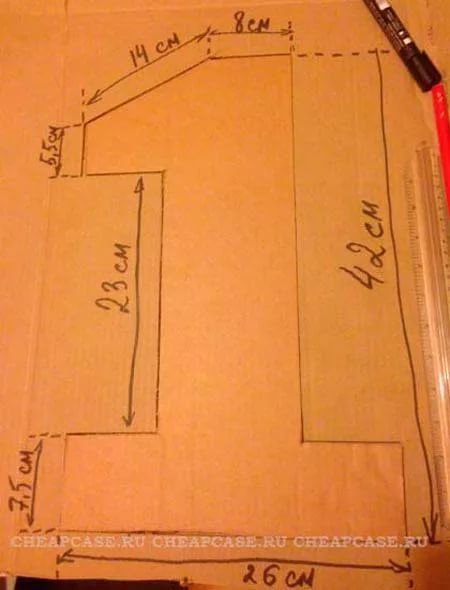 Нам необходимо будет нарезать множество кружочков одинакового диаметра, поэтому на картоне можно сделать шаблон, к примеру, обвести стакан и вырезать его.
Нам необходимо будет нарезать множество кружочков одинакового диаметра, поэтому на картоне можно сделать шаблон, к примеру, обвести стакан и вырезать его.
Гофру легко разрезать, даже если она сложена в несколько слоев, поэтому сначала мы нарежем лист на полосы. Их ширина должна быть на 0,5-1 см больше, чем диаметр круга-шаблона. Затем каждую полоску следует сложить несколько раз, чтобы в результате у нас получился многослойный квадрат. Каждый такой бумажный квадратик по середине (пересечение диагоналей) надо сколоть степлером. Далее на этом квадрате надо обвести нашу заготовку-круг и вырезать его по контуру, при этом скоба степлера должна располагаться по середине получившегося круга. Когда кружок будет готов, надо поднимать слой за слоем с самого верхнего, и аккуратно приминать их по направлению в центр. У нас получиться пушистый цветочек, который можно приклеить на основу.
Как сделать цифру из гофрированной бумаги
Объемная цифра 1 на годик из гофрированной бумаги может быть украшена пушистыми «хризантемами». Для их выполнения гофру следует также нарезать на полосы, затем сложить в несколько слоев и нарезать травкой, не дорезая до конца полосы с одного края. «Травка» должна быть по всей длине полосы, но получившеюся бахрому следует немного подкрутить пальцами, чтобы получились лепестки-иголочки. Осталось только скрутить полосу в плотный рулон и обвязать несколько раз ниткой. У вас получиться цветочек, у которого одна сторона будет пушистой, а вторая – плотный рулончик, который можно смазать клеем и приклеить к поверхности заготовки.
Для их выполнения гофру следует также нарезать на полосы, затем сложить в несколько слоев и нарезать травкой, не дорезая до конца полосы с одного края. «Травка» должна быть по всей длине полосы, но получившеюся бахрому следует немного подкрутить пальцами, чтобы получились лепестки-иголочки. Осталось только скрутить полосу в плотный рулон и обвязать несколько раз ниткой. У вас получиться цветочек, у которого одна сторона будет пушистой, а вторая – плотный рулончик, который можно смазать клеем и приклеить к поверхности заготовки.
Используя гофрированную полосу, у которой полосы будут идти перпендикулярно длине, можно скрутить миниатюрную розочку. Для этого бумагу вновь необходимо нарезать на полоски, а у каждой полосы один край сделать волнистым, растягивая его пальчиками. Готовую полосу надо скрутить в плотный рулон и зафиксировать край нитками, обвязав рулончик несколько раз.
Карточки по английскому
Карточки для печати, разной формы и размера, с буквами, цифрами, словами и картинками с названием на английском языке, транскрипцией, произношением и переводом на русский язык. Для подготовки и проведения уроков и занятий по английскому языку.
Для подготовки и проведения уроков и занятий по английскому языку.
Произношение на карточках передано при помощи транскрипционных знаков, если вы не умеете читать транскрипцию — Транскрипция
Карточки представленные на сайте находятся в формате: PDF, PNG или JPG. Если вам нужны карточки для распечатки, скачивайте pdf, этот формат лучше всего подходит для печати и позволяет сохранить указанный размер, если вам нужны обычные картинки, например, для вставки в Word, скачивайте png или jpg.
Карточки для занятий по английскому:
- Карточки «Время на английском»
- Карточки «Дни недели»
- Карточки «Названия месяцев»
- Карточки «Времена года»
- Карточки «Одежда»
- Карточки «Цвета на английском»
- Карточки с фруктами
- Карточки «Профессии на английском»
- Карточки «Моя семья»
- Распечатать карточки с транскрипцией
- Символы и фигуры на карточках
- Карточки квадратной формы с буквами.

Если вам понравились карточки, вы можете поблагодарить автора:
Карточки с буквами английского алфавита:
- Карточки с английскими буквами ( С картинками и словами )
- Карточки 9 на 10 с буквами и картинками
- Карточки 9 на 10 с буквами и картинками. черно-белые
- черно-белые карточки с буквами ( С картинками и словами )
- Английский алфавит на карточках ( Буквы без картинок, 5 на 5 см. )
- Алфавит на карточках на листе а4 ( Прописные и строчные, без картинок, 5 на 5 см. )
- Заглавные буквы на карточках( Заглавные без картинок, 5 на 5 см. )
- Буквы на карточках с произношением ( Карточки 5 на 5 см. с транскрипцией.)
- Карточки с буквами и произношением на листе а4 ( Карточки 5 на 5 см.)
- Карточки 5 на 5 гласные и согласные
- Карточки 5×5 см. Алфавит с произношением и словами
- Карточки 14×9 см. Письменные, прописные и строчные буквы
- Карточки 5×5 см., с алфавитом и картинками.
- Карточки 6×6 см., с алфавитом и картинками.
- Карточки 7×7 см., с алфавитом и картинками.

Карточки с английской транскрипцией:
- Карточки 7,5×10 см., с транскрипцией.
- Карточки 7,5×10 см., с транскрипцией. Страница 2.
- Карточки 7,5×10 см., с транскрипцией. Страница 3.
- Черно-белые карточки 7,5×10 см., с транскрипцией.
- Черно-белые карточки 7,5×10 см., с транскрипцией. Страница 2.
- Черно-белые карточки 7,5×10 см., с транскрипцией. Страница 3.
- Распечатать карточки с транскрипцией (Главная страница раздела)
Карточки «Время суток»:
- Карточки 7,5×10 см. «Время на английском».
- Карточки 7,5×10 см. «Время на английском». Страница 2
- Черно-белые карточки 7,5×10 см. «Время на английском». Страница 3
- Черно-белые карточки 7,5×10 см. «Время на английском». Страница 4
- Карточки 14×9 см. «Время суток».
- Карточки 14×9 см. «Время суток». Страница 2
- Черно-белые карточки 14×9 см. «Время суток». Страница 3
- Черно-белые карточки 14×9 см. «Время суток». Страница 4
- Карточки «Время на английском» (Главная страница раздела)
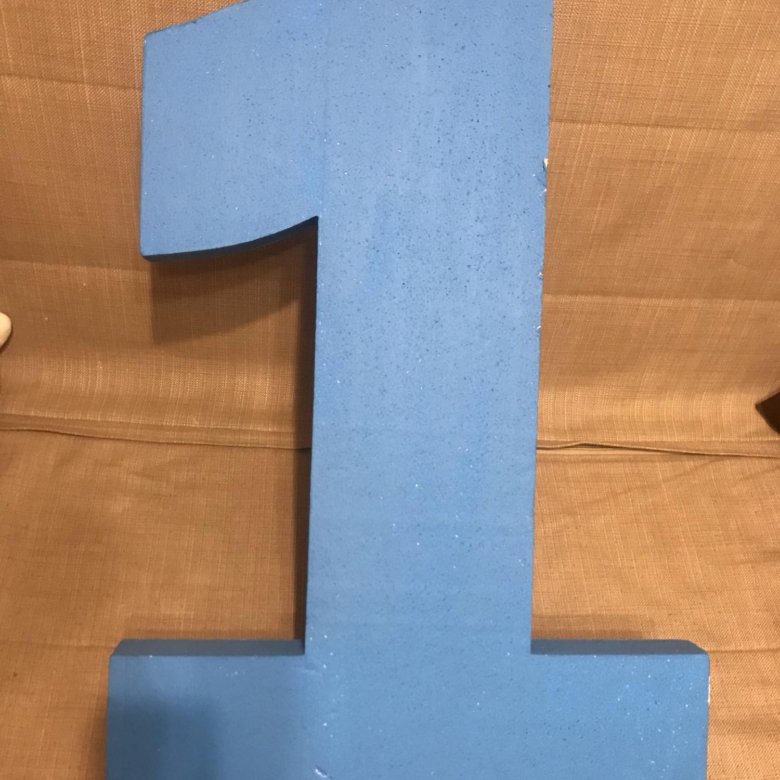 «Время суток». Страница 3
«Время суток». Страница 3Карточки с названиями профессий:
- Цветные карточки 14×9 см., с названиями профессий
- Черно-белые карточки 14×9 см., с названиями профессий
- Цветные карточки 7,5×10 см., с названиями профессий
- Карточки «Профессии на английском» (Главная страница раздела)
Карточки одежда и обувь:
- Карточки 14×9 см. «Одежда и обувь».
- Черно-белые карточки 14×9 см. «Одежда и обувь».
- Карточки 9×10 см. «Одежда и обувь».
- Черно-белые карточки 9×10 см. «Одежда и обувь».
- Карточки 75×100 мм. «Одежда на английском».
- Карточки «Одежда» (Главная страница раздела.)
Карточки с цифрами:
- Карточки 14 на 9 см. Количественные числительные
- Карточки 14 на 9 см. Порядковые числительные
- Карточки 9 на 10 см. Десятки от 10 до 100
- Карточки 5 на 5 см. Числа от 1 до 100
- Карточки, четные и нечетные числа от 1 до 100 ( Нечетные синие, четные зеленые. )
 Числа от 1 до 100
Числа от 1 до 100Фигуры и символы:
- Математические символы на карточках
- Карточки с геометрическими фигурами
- Объемные геометрические фигуры
- PDF — Лучше всего подходит для распечатки, при печати сохраняется указанный размер карточек. Формат листов A4.
- PNG — Обычные картинки, можно вставлять в Word или загружать на сайт.
Скачать в формате PDF
Карточки 5×5 см. с буквами.
- Заглавные буквы, черно-белые. Скачать
- Заглавные буквы, цветные. Скачать
- Прописные и строчные буквы, черно-белые. Скачать
- Прописные и строчные буквы, цветные. Скачать
- Буквы с произношением и транскрипцией, черно-белые. Скачать
- Буквы с произношением и транскрипцией, цветные. Скачать
- Гласные красным цветом, согласные синим. С транскрипцией и произношением .Скачать
- Буквы и слова на эту букву, с транскрипцией и произношением. Разноцветные. Скачать
 Разноцветные. Скачать
Разноцветные. СкачатьКарточки 5×5 см. с цифрами.
- Цифры от одного до ста и дроби с названием. Черно-белые. Скачать
- Цифры от одного до ста и дроби с названием. Разноцветные. Скачать
- С названием и транскрипцией, от 1 до 100. Черно-белые. Скачать
- С названием и транскрипцией, от 1 до 100. Цветные. Скачать
- С названием и транскрипцией, от 1 до 100. Серые. Скачать
- Карточки с нечетными числами синие, с четными зеленые. Скачать
Карточки 9×10 см. буквами.
- Черно-белые с буквами без картинок Скачать
- Цветные с буквами без картинок Скачать
- Черно-белые с буквами, произношением и картинками Скачать
- Цветные с буквами, произношением и картинками Скачать
- Заглавные буквы с транскрипцией и произношением, черно-белые Скачать
- Заглавные буквы с транскрипцией и произношением, цветные Скачать
Карточки 9×10 см. с цифрами.
- От одного до сто, черно-белые Скачать
- От одного до сто, цветные Скачать
- От одного до сто, четные зеленые, нечетные красные Скачать
- Десятки от 10 до 100. Цветные. Скачать
- Десятки от 10 до 100. Черно-белые. Скачать
 Цветные. Скачать
Цветные. СкачатьКарточки 14×9 см. с буквами.
- Заглавная и строчная с транскрипцией, произношением и картинкой. Цветные Скачать
- Заглавная и строчная с транскрипцией, произношением и картинкой. Old version. Скачать
- Заглавная и строчная с транскрипцией, произношением и картинкой. Черно-белые Скачать
- Прописная и строчная с транскрипцией и схемой написания букв от руки. С письменными буквами. Скачать
Карточки 14×9 см. с цифрами.
- Количественные числительные от 1 до 10 с палочками для счета. Цветные. Скачать
- Порядковые числительные от 1 до 10 с палочками для счета. Цветные. Скачать
- Количественные числительные от 1 до 10 с зайцами для счета. Цветные. Скачать
- Количественные числительные от 1 до 10 с транскрипцией и переводом. Цветные. Скачать
- Количественные числительные от 1 до 10 с транскрипцией и переводом. Черно-белые. Скачать
Буквы на весь лист, формата A4.

- Заглавные буквы, контуры. Не раскрашеные. Скачать
Символы и фигуры.
- Карточки 9×10 см. Основные математические символы. Цветные. Скачать
- Карточки 9×10 см. Основные математические символы. Черно-белые. Скачать
- Карточки 9×10 см. Геометрические фигуры. Цветные. Скачать
- Карточки 9×10 см. Геометрические фигуры. Черно-белые. Скачать
- Карточки 9×10 см. Объемные геометрические фигуры. Цветные. Скачать
- Карточки 9×10 см. Объемные геометрические фигуры. Черно-белые. Скачать
Скачать в формате PNG
Карточки 5×5 см. с буквами
- Строчная и заглавная, без транскрипции, каждая карточка отдельная картинка. Разноцветные. Скачать
- Буквы с произношением и транскрипцией, цветные. Скачать
- Буквы с произношением и транскрипцией, цветные. На листах. Скачать
- Гласные красным цветом, согласные синим. С транскрипцией и произношением. Скачать
- Буквы и слова на эту букву, с транскрипцией и произношением. Разноцветные. Скачать
 Разноцветные. Скачать
Разноцветные. СкачатьКарточки 5×5 см. с цифрами.
- Цветные с названием и транскрипцией, от 1 до 100. Скачать
- Карточки с нечетными числами синие, с четными зеленые. Скачать
Карточки 9×10 см. буквами.
- Прописная и строчная с транскрипцией, произношением и картинками. Черно-белые. Скачать
- Прописная и строчная с транскрипцией, произношением и картинками. Цветные. Скачать
Карточки 9×10 см. с цифрами.
- Десятки от 10 до 100. Черно-белые. Скачать
- Десятки от 10 до 100. Цветные. Скачать
- Десятки от 10 до 100. Серые. Скачать
- Десятки от 10 до 100. Контуры. Скачать
Карточки 14×9 см. с буквами.
- Заглавная и строчная с транскрипцией, произношением и картинкой. Черно-белые. Скачать
- Заглавная и строчная с транскрипцией, произношением и картинкой. Цветные. Скачать
- Прописная и строчная с транскрипцией и схемой написания букв от руки. С письменными буквами. Скачать
 Скачать
СкачатьКарточки 14×9 см. с цифрами.
- Количественные числительные от 1 до 10 с палочками для счета. Цветные. Скачать
- Порядковые числительные от 1 до 10 с палочками для счета. Цветные. Скачать
Символы и фигуры.
- Карточки 9×10 см. Основные математические символы. Цветные. Скачать
- Карточки 9×10 см. Геометрические фигуры. Цветные. Скачать
- Карточки 9×10 см. Геометрические фигуры. Черно-белые. Скачать
- Карточки 9×10 см. Объемные геометрические фигуры. Цветные. Скачать
- Карточки 9×10 см. Объемные геометрические фигуры. Черно-белые. Скачать
Если вам понравились карточки, вы можете поблагодарить автора:
Руководство для начинающих по сопоставлению любого шаблона с использованием регулярных выражений в R | by Rashida Nasrin Sucky
Это проще, чем вы думаете
Регулярное выражение — это не что иное, как последовательность символов, соответствующая образцу в фрагменте текста или текстовом файле. Он используется при анализе текста во многих языках программирования. Символы регулярного выражения очень похожи во всех языках. Но функции извлечения, поиска, обнаружения и замены могут быть разными в разных языках.
Он используется при анализе текста во многих языках программирования. Символы регулярного выражения очень похожи во всех языках. Но функции извлечения, поиска, обнаружения и замены могут быть разными в разных языках.
В этой статье я буду использовать R. Но вы можете узнать, как использовать регулярное выражение из этой статьи, даже если вы хотите использовать какой-то другой язык. Это может показаться слишком сложным, когда вы этого не знаете. Но, как я упоминал в начале, это проще, чем вы думаете. Я постараюсь объяснить это настолько, насколько смогу. Вы можете задавать мне вопросы в разделе комментариев, если вы не поняли какую-либо часть.
Здесь мы будем учиться на практике. Я начну с самых простых идей и постепенно перейду к более сложным паттернам.$|?*+», Извлечь все точки или периоды из этих текстов: В R есть функция str_extract_all, которая извлекает все точки из этих строк. Вывод: Внимательно посмотрите на вывод: в третьей строке одна точка, в четвертой строке одна точка, а в шестой строке две точки Попробуйте сами.Я буду использовать str_extract_all для всех демонстраций в этой статье, чтобы найти все это. :
«coreyms.com»,
«321-555-4321»,
«123.555.1234»,
«123*555*1234»
)  Эта функция принимает два параметра. Во-первых, тексты, представляющие интерес, и во-вторых, элемент, который необходимо извлечь.
Эта функция принимает два параметра. Во-первых, тексты, представляющие интерес, и во-вторых, элемент, который необходимо извлечь. str_extract_all(ch, "\\.")
[[1]]
символов (0)[[2]]
символов (0)[[3]]
[1] "."[[4]]
[1] "."[[5]]
символов(0)[[6]]
[1] "." "."[[7]]
символов(0)
- .] = соответствует символам Не в подставках
14. | = Либо Или15. ( ) = Группа
16. *= 0 или более
17. + = 1 или более
18. ? = Да или Нет
19. {x} = Точное число
20. {x, y} = Диапазон чисел (максимум, минимум)
Мы продолжим обращаться к этому списку выражений при дальнейшей работе.
Мы будем работать над каждым из них сначала индивидуально, а затем в группах.
Начиная с основ
Согласно приведенному выше списку, ‘\d’ улавливает цифры.
Извлечь все цифры из ‘ch’:
str_extract_all(ch, "\\d")
Вывод:
[[1]]
символ(0) ]
символов(0)[[3]]
символов(0)[[4]]
символов(0)[[5]]
[1] "3" "2" "1" "5" "5" "5" "4" "3" "2" "1"[[6]]
[1] "1" "2" "3" "5" "5" "5" "1" "2" "3" " "4"[[7]]
[1] "1" "2" "3" "5" "5" "5" "1" "2" "3" "4"Первые четыре строки не имеют цифр. Последние три строки — номера телефонов.» «$» «|» «?» «*» «+»[[5]]
[1] «c» «o» «r» «e» «y» «m» «s» «.» » c» «o» «m»[[6]]
[1] «-» «-«[[7]]
[1] «.» «.»[[8]]
[1] «*» «*»Посмотрите, он извлек буквы, точки и другие специальные символы, но не извлек ни одной цифры.
‘w’ соответствует символам слова, включающим az, AZ, 0–9 и ‘_’.
Давайте проверим.str_extract_all(ch, "\\w")
Вывод:
[[1]]
[1] "a" "b" "c" "d" "e" "f" "g" "h ""i"[[2]]
[1] "A" "B" "C" "D" "E" "F" "G" "H" "I"[[3]]
[1] " T" "h" "i" "s" "i" "s" "m" "e"[[4]]
символов(0)[[5]]
[1] "c" "o" "r ""e" "y" "m" "s" "c" "o" "m"[[6]]
[1] "3" "2" "1" "5" "5" "5" " 4" "3" "2" "1"[[7]]
[1] "1" "2" "3" "5" "5" "5" "1" "2" "3" "4" [[8]]
[1] "1" "2" "3" "5" "5" "5" "1" "2" "3" "4"В нем есть все, кроме точек и специальных символов.» «$» «|» «?» «*» «+»[[5]]
[1] «.»[[6]]
[1] «-» «-»Я перейду, чтобы показать ‘b’ и ‘B’ теперь. ‘b’ улавливает границу слова. Вот пример:
st = "This is Bliss"
str_extract_all(st, "\\bis")Вывод:
[[ 1]]
[1] "is"В строке только одно «is». Так что мы могли бы поймать его здесь. Давайте посмотрим на использование «B»
st = "This is Bliss"
str_extract_all( st, "\\Bis")Вывод:
[[1]]
[1] "is" "is"В строке ‘st’ есть два других ‘is’, которые не входят в границу.
’ и ‘$’, которые обозначают начало и конец строк соответственно. Вот пример:
sts = c("Это я",
"Это мой дом",
"Привет, мир!")Найти все восклицательные знаки в конце предложения.
str_extract_all(sts, "!$")
Вывод:
[[1]]
символов(0)[[2]]
символов(0)[[3]]
[1] "!"У нас есть только одно предложение, заканчивающееся восклицательным знаком. Если пользователи R хотят найти предложение, заканчивающееся восклицательным знаком:
sts[str_detect(sts, "!$")]
Вывод:
[1] "Привет, мир!"
Найдите предложения, начинающиеся с «Это».T»)]
Результат:
[1] "Это я" "Это мой дом"
‘[]’ соответствует символам или диапазонам в нем.
Для демонстрации приступим вернуться к ‘ch’. Извлечь все между 2 и 4.
str_extract_all(ch, "[2-4]")
Вывод:
[[1]]
символ(0)[[2]]
символ(0)[[3]]
символ(0)[[4]]
символ(0)[[5]]
[1] "3" "2" "4" "3" "2"[[ 6]]
[1] "2" "3" "2" "3" "4"[[7]]
[1] "2" "3" "2" "3" "4"Давайте перейдем к более крупному эксперименту
Извлеките телефонные номера только из ‘ch’.
Я объясню шаблон после того, как вы увидите вывод:str_extract(ch, "\\d\\d\\d.\\d\\d\\d.\\d\\d\\d\\d ")
Вывод:
[1] NA NA NA
[4] NA "321-555-4321" "123.555.1234"
[7] "123*555*1234"В приведенном выше регулярном выражении каждый ‘\\d’ означает цифру, а ‘.’ может соответствовать чему угодно между ними (посмотрите на число 1 в списке выражений в начале). Итак, мы получили цифры, затем специальный символ между ними, еще три цифры, затем снова специальные символы, затем еще 4 цифры.Таким образом, все, что соответствовало этим критериям, было извлечено.
Регулярное выражение для указанного выше номера телефона также можно записать следующим образом.
str_extract(ch, "\\d{3}.\\d{3}.\\d{4}")Вывод:
[1] NA NA NA
[4] NA "321-555 -4321" "123.555.1234"
[7] "123*555*1234"Посмотрите на номер 19 списка выражений. {x} означает точное число. Здесь мы использовали {3}, что означает ровно 3 раза.
‘\\d{3}’ означает три цифры.Но обратите внимание, что «*» между цифрами не является обычным форматом телефонного номера. Обычно «-» или «.» могут использоваться в качестве разделителя в телефонных номерах. Правильно? Давайте сопоставим это и исключим номер телефона с «*». Потому что это может выглядеть как 10-значный номер телефона, но может и не быть номером телефона. Мы хотим придерживаться обычного формата номера телефона.
str_extract(ch, "\\d{3}[-.]\\d{3}[-.]\\d{4}")Вывод:
[1] NA NA NA
[4 ]НА "321-555-4321" "123.555.1234"
[7] NAСмотрите, это соответствует только обычному формату номера телефона. В этом выражении после трех цифр мы явно упомянули «[-.]», что означает, что требуется соответствие только «-» или точке (‘.’).
Вот список телефонных номеров:
ph = c("543-325-1278",
"900-123-7865",
"421.235.9845",
"453* 2389*4567",
"800-565-1112",
"361 234 4356"
)Если мы используем приведенное выше выражение для этих телефонных номеров, то получится следующее:
str_extract(ph, "\\d {3}[-. ]\\d{3}[-.]\\d{4}") Вывод:
[1] "543-325-1278" "900-123-7865" "421.235.9845"
[4 ] NA "800-565-1112" NAСмотрите! Этот формат исключает «361 234 4356». Иногда мы не используем никаких разделителей между ними, а просто используем пробел, верно? Кроме того, первая цифра номера телефона в США не 0 и не 1. Это число от 2 до 9. Все остальные цифры могут быть любыми от 0 до 9. Давайте позаботимся об этом шаблоне.
p = "([2-9][0-9]{ 2})([- .]?)([0-9]{3})([- .])?([0-9]{4})"
str_extract(ph, p)Здесь я сохранил шаблон отдельно.
В регулярном выражении ‘()’ используется для обозначения группы. Посмотрите на номер 15 списка выражений
Вот разбивка приведенных выше выражений
Первая группа была «([2–9][0–9]{2})»:
‘[2–9]’ представляет одну цифру от 2 до 9
‘[0–9]{2}’ представляет две цифры от 0 до 9
Вторая группа была «([- .]?)»:
‘[-.]’ означает, что это может быть ‘-‘ или ‘.’
с использованием «?» после этого означает, что «-» и «.
» являются необязательными. Так что, если он пустой, это тоже нормально.Думаю, с остальными группами тоже все ясно.
Вот результат выражения выше:
[1] "543-325-1278" "900-123-7865" "421.235.9845"
[4] NA "800-565-1112" "361 234 4356"Находит номер телефона с «-«, «.», а также с пробелами в качестве разделителя.
Что делать, если нам нужно найти номер телефона, который начинается с 800 и 900.
p = "[89]00[-.]\\d{3}[-.]\\d{4}"
str_extract_all(ph, p)Вывод:
[[1]]
символов (0)[[2]]
[1] "900-123-7865"[[3]]
символов(0)[[4]]
символов(0)[[5]]
[1] "800 -565-1112"[[6]]
символ(0)Давайте разберемся с приведенным выше регулярным выражением: «[89]00[-.]\\d{3}[-.]\\d{4}» .
Первый символ должен быть 8 или 9. Этого можно добиться с помощью [89].
Следующие два элемента будут нулями. Мы прямо упомянули об этом.
Затем «-» или «.», которые можно получить с помощью [-.
].Следующие три цифры = \\d{3}
Снова ‘-‘ или ‘.’ = [-.]
Еще четыре цифры в конце = \\d{4}
Извлечь разные форматы адресов электронной почты
Адреса электронной почты немного сложнее, чем телефонные номера. Потому что адрес электронной почты может содержать буквы верхнего регистра, буквы нижнего регистра, цифры, специальные символы и все такое. Вот набор адресов электронной почты:
email = c("[email protected]",
"[email protected]",
"[email protected]",
"[email protected]")Мы разработаем регулярное выражение, которое будет извлекать все эти адреса электронной почты:
Сначала обработайте часть перед символом @.Эта часть может содержать строчные буквы, которые можно обнаружить с помощью [az], прописные буквы, которые можно определить с помощью [AZ], цифры, которые можно найти с помощью [0– 9], а также специальные символы, такие как «.
» и «_». Все они могут быть упакованы так:«[a-zA-Z0–9-.]+»
Знак «+» указывает на один или несколько из этих символов (посмотрите на номер 17 в списке выражений). Потому что мы не знаем, сколько там может быть разных букв, цифр или цифр. Так что на этот раз мы не можем использовать {x} так, как мы это делали для телефонных номеров.
Теперь поработайте над частью между «@» и «.». Эта часть может состоять из букв верхнего регистра, букв нижнего регистра и цифр, которые могут быть распознаны как:
«[a-zA_Z0–9]+»
Наконец, часть после ‘.’. Здесь у нас их четыре: «com», «net», «edu», «org». Этих четырех можно поймать с помощью группы:
«(com|edu|net|org»)
Здесь символ «|» используется для обозначения «или-или». Посмотрите на номер 14 списка выражений в начале.
Вот полное выражение:
p = "[a-zA-Z0-9-.]+@[a-zA_Z0-9]+\\.(com|edu|net|org)"
str_extract_all( электронная почта, p)Вывод:
[[1]]
[1] "RashNErel@gmail. com"[[2]]
[1] "[email protected]"[[3]]
[1] "48@уни.edu"[[4]]
[1] "[email protected]"Это также будет работать, если вы не укажете части после точек. Поскольку мы добавили знак «+» после второй части, это означает, что это будет принимать любое количество символов после этого.
Но если вам нужен определенный тип домена, такой как «com» или «net», вы должны явно указать их, как мы сделали в предыдущем выражении.
p = "[ a-zA-Z0-9-.]+@[a-zA_Z0-9-.]+"
str_extract_all(email, p)Вывод:
[[1]]
[1] "[email protected]"[[2]]
[1] "[email protected]"[[3]]
[1] "[email protected]"[[4]]
[1] "nerel@stb. com"Другим распространенным сложным типом являются URL-адреса
Вот список URL-адресов:
urls = c("https://regenerativetoday.com",
"http://setf.ml ",
"https://www.yahoo.com",
"http://studio_base. net",
)Может начинаться с «http» или «https». Чтобы определить, что это выражение можно использовать :
‘https?’
Это означает, что ‘http’ останется нетронутым.Затем следует знак «?» после «s». Таким образом, «s» является необязательным. Может быть, а может и не быть.
Другая необязательная часть после термина «://»: «www». Мы можем определить его, используя:
«(www\\.)?»
Как мы работали ранее, ‘()’ используется для группировки некоторых выражений. Здесь мы группируем «www» и «.». После круглой скобки ‘?’ означает, что весь этот термин внутри круглой скобки является необязательным. Они могут быть, а могут и не быть.
Затем доменное имя. В этом наборе адресов электронной почты у нас есть только строчные буквы и «_».Итак, [a-z-] будет работать. Но в общем доменное имя может содержать как буквы верхнего регистра, так и цифры. Итак, мы будем использовать:
«\\w+»
Посмотрите на число 4 в списке выражений.
‘\\w’ обозначает символ слова, который может включать строчные буквы, прописные буквы и цифры. Знак «+» указывает на то, что таких символов может быть один или несколько.После домена идет еще одна точка и еще несколько символов. Мы получим их, используя:
«\\.\\w+»
Помните, если вы используете только точку (.) сопоставить точку не получится. Потому что только одна точка соответствует любому символу. Если вам нужно сопоставить только буквальную точку (.), вам нужно поставить ее как ‘\\.’
Здесь мы использовали одну точку, обозначенную «\\.», затем символы слова «\\w» и Знак «+» указывает на наличие дополнительных символов.
Давайте сложим:
p = "https?://(www\\.)?\\w+\\.\\w+"
str_extract_all(urls, p)Вывод:
[[1 ]]
[1] "https://regenerativetoday.com"[[2]]
[1] "http://setf.ml"[[3]]
[1] "https://www.yahoo.com"[[4]]
[1] "http://studio_base.com"Вы можете получить только ‘.
com или ‘.net’. Это можно указать явно.p = "https?://(www\\.)?(\\w+)(\\.)+(com|net)"
str_extract_all (urls, p)Вывод:
[[1]]
[1] "https://regenerativetoday.com"[[2]]
символов(0)[[3]]
[1] "https ://www.yahoo.com"[[4]]
[1] "http://studio_base.com"Видите ли, он получает только домены «.com» или «.net» и исключает «.ml’ домен, который у нас был.
Наконец, поработайте над набором имен
Это тоже может быть немного сложно. Вот набор имен:
name = c("Мистер Джон",
"Миссис Джон",
"Мистер Рон",
"Мисс Рин",
"Мисс Джули")Смотри, это может начинаться с Mr, Ms или Mrs. Иногда ставится точка после Mr, иногда нет. Давайте сначала поработаем над этой частью. Во всех них буква «М» является общей. Оставьте его нетронутым и создайте группу, используя остальные, например:
«M(r|s|rs)»
После «M» может быть «r», или «s», или «rs».
Затем необязательная точка, которую можно получить, используя:
«\\.?»
Пробел после которого можно обнаружить с помощью:
«\\s»
После того, как имя пространства начинается с заглавной буквы, которую можно ввести с помощью:
[AZ]»
После этого заглавной буквы буквы, есть некоторые строчные буквы, и мы не знаем точно, сколько. Итак, мы будем использовать это:
«\\w*»
Посмотрите на число 16 в списке выражений.«*» означает 0 или более. Итак, мы говорим, что может быть 0 или более словесных символов.
Собираем все вместе:
p = "M(r|s|rs)\\.?[AZ\\s]\\w*"
str_extract_all(name, p)Вывод:
[[ 1]]
[1] "Мистер Джон"[[2]]
[1] "Миссис Джон"[[3]]
[1] "Мистер Рон"[[4]]
[1] "Мисс .Рин"[[5]]
[1] "Мисс Джули"Поздравляем! Вы работали над некоторыми сложными и интересными шаблонами, которые должны дать вам достаточно знаний, чтобы использовать регулярное выражение для сопоставления практически с любым шаблоном.
Заключение
Это еще не все. В регулярном выражении гораздо больше. Но если вы новичок, вы должны гордиться собой, что вы прошли долгий путь. Теперь вы должны быть в состоянии сопоставить практически любой шаблон. Позже я сделаю еще один учебник по расширенному регулярному выражению. Но вы должны быть в состоянии начать использовать регулярные выражения сейчас, чтобы сделать что-то классное.
Не стесняйтесь подписываться на меня в Twitter и лайкать мою страницу в Facebook.
Учебник по регулярным выражениям => Сопоставление различных чисел
Пример
[a-b], где a и b — цифры в диапазоне от0до9[3-7] будет соответствовать одной цифре в диапазоне от 3 до 7.Совпадение нескольких цифр
\d\d будет соответствовать 2 последовательным цифрам \d+ будет соответствовать 1 или более последовательным цифрам \d* будет соответствовать 0 или более последовательным цифрам \d{3} будет соответствовать 3 последовательным цифрам \d{3,6} будет соответствовать от 3 до 6 последовательных цифр \d{3,} будет соответствовать 3 или более последовательным цифрам\dв приведенных выше примерах можно заменить диапазоном чисел:[3-7][3-7] будет соответствовать 2 последовательным цифрам в диапазоне от 3 до 7 [3-7]+ будет соответствовать 1 или более последовательным цифрам в диапазоне от 3 до 7.
[3-7]* будет соответствовать 0 или более последовательным цифрам в диапазоне от 3 до 7.
[3-7]{3} будет соответствовать 3 последовательным цифрам в диапазоне от 3 до 7.
[3-7]{3,6} будет соответствовать от 3 до 6 последовательных цифр в диапазоне от 3 до 7.
[3-7]{3,} будет соответствовать 3 или более последовательным цифрам в диапазоне от 3 до 7.
Вы также можете выбрать определенные цифры:
[13579] будет соответствовать только «нечетным» цифрам [02468] будет соответствовать только "четным" цифрам 1|3|5|7|9 еще один способ сопоставления «нечетных» цифр — | символ означает ИЛИСовпадение чисел в диапазонах, содержащих более одной цифры:
\d|10 соответствует одной цифре от 0 до 10 ИЛИ 10.| символ означает ИЛИ [1-9]|10 соответствует цифре от 1 до 10 в диапазоне от 1 до 9 ИЛИ 10 [1-9]|1[0-5] соответствует цифре от 1 до 15 в диапазоне от 1 до 9 ИЛИ 1, за которой следует цифра от 1 до 5 \d{1,2}|100 соответствует от 0 до 100 от одной до двух цифр ИЛИ 100Совпадение чисел, которые делятся на другие числа:
\d*0 соответствует любому числу, которое делится на 10 - любому числу, оканчивающемуся на 0 \d*00 соответствует любому числу, которое делится на 100 — любому числу, оканчивающемуся на 00 \d*[05] соответствует любому числу, которое делится на 5 - любому числу, оканчивающемуся на 0 или 5 \d*[02468] соответствует любому числу, которое делится на 2 — любому числу, оканчивающемуся на 0,2,4,6 или 8.
совпадающих числа, которые делятся на 4 — любое число, которое равно 0, 4 или 8 или оканчивается на 00, 04, 08, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48, 52, 56, 60, 64, 68, 72, 76, 80, 84, 88, 92 или 96
[048]|\d*(00|04|08|12|16|20|24|28|32|36|40|44|48|52|56|60|64|68|72|76| 80|84|88|92|96)Можно сократить.Например, вместо
.20|24|28мы можем использовать2[048]. Кроме того, поскольку 40-е, 60-е и 80-е имеют одинаковый шаблон, мы можем включить их:[02468][048], а остальные тоже имеют шаблон[13579][26]. Таким образом, всю последовательность можно сократить до:[048]|\d*([02468][048]|[13579][26]) - числа, кратные 4Сопоставление чисел, которые не имеют шаблона, такого как числа, делящиеся на 2, 4, 5, 10 и т. д., не всегда может быть сделано кратко, и вам обычно приходится прибегать к диапазону чисел.Например, сопоставить все числа, которые делятся на 7 в диапазоне от 1 до 50, можно просто, перечислив все эти числа:
.7|14|21|28|35|42|49 или вы могли бы сделать это таким образом 7|14|2[18]|35|4[29]
Язык регулярных выражений — краткий справочник
- Статья
- 11 минут на чтение
Пожалуйста, оцените свой опыт
да Нет
Любая дополнительная обратная связь?
Отзыв будет отправлен в Microsoft: при нажатии кнопки отправки ваш отзыв будет использован для улучшения продуктов и услуг Microsoft.
Политика конфиденциальности.Представлять на рассмотрение
Спасибо.
В этой статье
Регулярное выражение — это шаблон, которому механизм регулярных выражений пытается сопоставить входной текст. Шаблон состоит из одного или нескольких символьных литералов, операторов или конструкций. Краткое введение см. в разделе Регулярные выражения .NET.
В каждом разделе этого краткого справочника перечислены определенные категории символов, операторов и конструкций, которые можно использовать для определения регулярных выражений.
Мы также предоставили эту информацию в двух форматах, которые вы можете скачать и распечатать для удобства:
Экранирование символов
Символ обратной косой черты (\) в регулярном выражении указывает, что символ, следующий за ним, либо является специальным символом (как показано в следующей таблице), либо должен интерпретироваться буквально.
Дополнительные сведения см. в разделе Экранирование символов.Экранированный символ Описание Узор Совпадения \аСоответствует символу колокольчика, \u0007. \"\u0007"в"Ошибка!" + '\ u0007'\бВ классе символов соответствует символу возврата, \u0008. [\b]{3,}"\b\b\b\b"в"\b\b\b\b"\ тСоответствует вкладке, \u0009. (\w+)\t"item1\t","item2\t"в"item1\titem2\t"Соответствует возврату каретки, \u000D.( \rне эквивалентен символу новой строки,\n.)\r\n(\w+)"\r\nЭти"в"\r\nЭти\nдве строки. " \vСоответствует вертикальной вкладке, \u000B. [\v]{2,}"\v\v\v"в"\v\v\v"\фСоответствует переводу страницы, \u000C. [\f]{2,}"\f\f\f"в"\f\f\f"\нСоответствует новой строке, \u000A. \r\n(\w+)"\r\nЭти"в"\r\nЭти\nдве строки."\еСоответствует побегу, \u001B. \е"\x001B"в"\x001B"\нннИспользует восьмеричное представление для указания символа ( nnn состоит из двух или трех цифр). \ш\040\ш"a b","c d"в"a bc d"\xннИспользует шестнадцатеричное представление для указания символа ( nn состоит ровно из двух цифр). \ш\х20\ш"a b","c d"в"a bc d"\cX\cxСоответствует управляющему символу ASCII, который указан как X или x , где X или x — это буква управляющего символа. \кС"\x0003"в"\x0003"(Ctrl-C)\иннннСоответствует символу Unicode, используя шестнадцатеричное представление (ровно четыре цифры, представленные nnnn ). \w\u0020\w"a b","c d"в"a bc d"\Если за ним следует символ, который не распознается как escape-символ в этой и других таблицах этого раздела, соответствует этому символу. Например, \*совпадает с\x2Aи\.совпадает с \x2E. Это позволяет обработчику регулярных выражений устранять неоднозначность языковых элементов (таких как * или ?) и символьных литералов (представленных как\*или\?).\d+[\+-x\*]\d+"2+2"и"3*9"в"(2+2) * 3*9"Классы символов
Класс символов соответствует любому из набора символов. Классы символов включают языковые элементы, перечисленные в следующей таблице. Дополнительные сведения см. в разделе Классы символов.
Класс символов Описание Узор Совпадения [группа символов]Соответствует любому одиночному символу из character_group .ай] "р","г","н"в"царствование"[первый-последний]Диапазон символов: соответствует любому одиночному символу в диапазоне от первых до последних . [А-Я]"А","В"в"AB123".Подстановочный знак: соответствует любому одиночному символу, кроме \n. Чтобы совпасть с буквальным символом точки (. или
\u002E), вы должны предварить его escape-символом (\.)."авеню"в"ступицу""ели"в"воду"\p{имя}Соответствует любому одиночному символу в общей категории Unicode или именованному блоку, заданному name . \p{Lu}\p{IsCyrillic}"C","L"в"City Lights""Д","Ж"в"ДЖем"\P{имя}Соответствует любому одиночному символу, не входящему в общую категорию Unicode или именованный блок, указанный в name . \P{Lu}\P{IsCyrillic}"i","t","y"in"City""e","m"in"ДЖem"\шСоответствует любому символу слова. \ш"I","D","A","1","3"в"ID A1.3"\ВтСоответствует любому символу, не являющемуся словом. \Вт"","."в"ID A1.3"Соответствует любому символу пробела. "D"в"ID A1.3"\ССоответствует любому непробельному символу. \с\с"_"в"int __ctr"\дСоответствует любой десятичной цифре. \д"4"в"4 = IV"\DСоответствует любому символу, кроме десятичной цифры. \D"","=","","I","V"в"4 = IV"Анкеры
Якоря, или атомарные утверждения нулевой ширины, приводят к успешному или неудачному совпадению в зависимости от текущей позиции в строке, но они не заставляют движок продвигаться по строке или потреблять символы.\д{3}
"901"в"901-333-"$По умолчанию совпадение должно находиться в конце строки или перед \nв конце строки; в многострочном режиме он должен располагаться до конца строки или до\nв конце строки.-\d{3}$"-333"в"-901-333"\АСовпадение должно происходить в начале строки. \A\d{3}"901"в"901-333-"\ЗСовпадение должно находиться в конце строки или перед \nв конце строки.-\d{3}\Z"-333"в"-901-333"\зСовпадение должно находиться в конце строки. -\d{3}\z"-333"в"-901-333"\ГСовпадение должно произойти в точке, где закончилось предыдущее совпадение. \Г\(\д\)"(1)","(3)","(5)"в"(1)(3)(5)[7](9)"\бСовпадение должно происходить на границе между символом \w(буквенно-цифровой) и символом\W(не буквенно-цифровой).\b\w+\s\w+\b"тема их","тема их"в"тема их их"\БСовпадение не должно происходить на границе \b.\Изгиб\w*\b"заканчивается","заканчивается"в"заканчивается посылает терпеть кредитор"Группирующие конструкции
Группирующие конструкции очерчивают подвыражения регулярного выражения и обычно захватывают подстроки входной строки. Группирующие конструкции включают языковые элементы, перечисленные в следующей таблице. Дополнительные сведения см. в разделе Конструкции группировки.
Группирующая конструкция Описание Узор Совпадения (подвыражение)Захватывает совпавшее подвыражение и присваивает ему порядковый номер, отсчитываемый от единицы. (\ш)\1"ее"в"глубокий"(? <Имя>Субпрессы)
или
(?Имя'Субпрессия)Захватывает совпавшее подвыражение в именованную группу. (?<двойной>\w)\k<двойной>"ее"в"глубокий"(? <Название1-Название2>>
)
или
(?Название1-Название2'Подключение)Определяет определение группы балансировки.((1-3)*(3-1))» (?:подвыражение)Определяет незахватываемую группу. Запись(?:Строка)?"WriteLine"в"Console.WriteLine()""Write"в"Console.Write(значение)"(?imnsx-imnsx:подвыражение)Применяет или отключает указанные параметры в подвыражении .Дополнительные сведения см. в разделе Параметры регулярных выражений. А\d{2}(?i:\w+)\b"A12xl","A12XL"в"A12xl A12XL a12xl"(?=подвыражение)Утверждение положительного просмотра вперед нулевой ширины. \b\w+\b(?=.+и.+)"кошки","собаки"
в
"кошки, собаки и некоторые мыши".(?!подвыражение)Утверждение отрицательного просмотра вперед нулевой ширины. \b\w+\b(?!.+и.+)"и","некоторые","мыши"
в
"кошки, собаки и некоторые мыши".(?<=подвыражение)Положительное ретроспективное утверждение нулевой ширины. \b\w+\b(?<=.+и.+)———————————
\b\w+\b(?<=.+и.*)"некоторые","мыши"
в
"кошки, собаки и некоторые мыши.
————————————
«и»,«некоторые»,«мыши»
в
«кошки, собаки и некоторые мыши».(? подвыражение)Отрицательное утверждение ретроспективного просмотра нулевой ширины. \b\w+\b(?———————————
\b\w+\b(?«кошки»,«собаки»,» и «
» в
«кошки, собаки и некоторые мыши.
————————————
«кошки»,«собаки»
в
«кошки, собаки и некоторые мыши».(?>подвыражение)Атомная группа. (?>а|аб)с"ac"в"ac"ничего в
"abc"Краткий обзор
Когда обработчик регулярных выражений встречает выражение просмотра , он берет подстроку, идущую от текущей позиции до начала (просмотр назад) или конца (просмотр вперед) исходной строки, а затем выполняет Регулярное выражение.IsMatch для этой подстроки, используя шаблон поиска. Затем успешность результата этого подвыражения определяется тем, является ли это утверждение положительным или отрицательным.
Осмотр Имя Функция (?=проверить)Положительный прогноз Утверждает, что то, что следует сразу за текущей позицией в строке, является «проверкой» (?<=проверить)Положительный просмотр назад Утверждает, что то, что непосредственно предшествует текущей позиции в строке, является «проверкой» (?!проверить)Отрицательный прогноз Утверждает, что то, что следует сразу за текущей позицией в строке, не является «проверкой» (?Отрицательный ретроспективный просмотр Утверждает, что то, что непосредственно предшествует текущей позиции в строке, не является "проверкой" После совпадения атомарных групп не будут повторно оцениваться, даже если оставшаяся часть шаблона не удалась из-за совпадения.
Это может значительно улучшить производительность, когда квантификаторы встречаются в атомарной группе или в остальной части шаблона.Квантификаторы
Квантификатор указывает, сколько экземпляров предыдущего элемента (который может быть символом, группой или классом символов) должно присутствовать во входной строке, чтобы произошло совпадение. Квантификаторы включают языковые элементы, перечисленные в следующей таблице. Для получения дополнительной информации см. Квантификаторы.
Квантификатор Описание Узор Совпадения *Соответствует предыдущему элементу ноль или более раз. \д*\.\д".0","19,9","219,9"+Соответствует предыдущему элементу один или несколько раз. "быть+""пчела"в"был","быть"в"согнутый"?Соответствует предыдущему элементу ноль или один раз. "дождь""побежал","дождь"{п}Соответствует предыдущему элементу ровно n раз. ",\d{3}"",043"в"1,043,6",",876",",543"и",210"в"9,876,549,2626" 32,625 9,876,549,243,226{п,}Соответствует предыдущему элементу не менее n раз. "\d{2,}""166","29","1930"{n,м}Соответствует предыдущему элементу не менее n раз, но не более m раз. "\d{3,5}""166","17668""19302"в"1"*?Соответствует предыдущему элементу ноль или более раз, но как можно меньше раз. \д*?\.\д".0","19,9","219,9"+?Соответствует предыдущему элементу один или несколько раз, но как можно меньше раз. "быть+?""быть"в"был","быть"в"согнут"??Соответствует предыдущему элементу ноль или один раз, но как можно меньше раз. "рай??н""побежал","дождь"{п}?Соответствует предыдущему элементу ровно n раз. ",\d{3}?"",043"в"1,043,6",",876",",543"и",210"в"9,876,549,2626" 32,625 9,876,549,243,226{п,}?Соответствует предыдущему элементу как минимум n раз, но как можно меньше раз. "\d{2,}?""166","29","1930"{н,м}?Соответствует предыдущему элементу между n и m раз, но как можно меньше раз. "\d{3,5}?""166","17668""193","024"в"1"Конструкции обратной ссылки
Обратная ссылка позволяет впоследствии идентифицировать ранее совпавшее подвыражение в том же регулярном выражении. В следующей таблице перечислены конструкции обратной ссылки, поддерживаемые регулярными выражениями в .NET. Дополнительные сведения см. в разделе Конструкции обратной ссылки.
Конструкция обратной ссылки Описание Узор Совпадения \номерОбратная ссылка. Соответствует значению нумерованного подвыражения.(\ш)\1"ее"в"искать"\k<имя>Именованная обратная ссылка. Соответствует значению именованного выражения. (?\w)\k "ее"в"искать"Альтернативные конструкции
Конструкции чередования модифицируют регулярное выражение, чтобы включить сопоставление либо/или. Эти конструкции включают языковые элементы, перечисленные в следующей таблице. Дополнительные сведения см. в разделе Конструкции чередования.
Альтернативная конструкция Описание Узор Совпадения |Соответствует любому элементу, разделенному вертикальной чертой ( |).й(е|ис|ат)"это","это"в"это день". (?(выражение)да|нет)Соответствует да , если шаблон регулярного выражения, обозначенный выражением , соответствует; в противном случае соответствует необязательной части no . выражение интерпретируется как утверждение нулевой ширины. (?(А)А\d{2}\b|\b\d{3}\b)"A10","910"в"A10 C103 910"(?(название)да|нет)Совпадения да , если name , именованная или пронумерованная группа захвата, имеет совпадение; в противном случае соответствует необязательному no . (?")?(?(quoted).+?"|\S+\s) "Собаки.jpg","\"Йиска играет.в jpg\"" "Собаки.jpg \"Йиска играет.jpg\""Замена
Замены — это элементы языка регулярных выражений, которые поддерживаются в шаблонах замены. Дополнительные сведения см. в разделе Замены. Метасимволы, перечисленные в следующей таблице, являются атомарными утверждениями нулевой ширины.
Символ Описание Узор Сменный шаблон Строка ввода Строка результата $номерЗаменяет подстроку, совпавшую с группой , на число . \b(\w+)(\s)(\w+)\b$3 $2 $1"раз два""два один"${имя}Заменяет подстроку, соответствующую именованной группе name . \b(?\w+)(\s)(? \w+)\b ${слово2} ${слово1}"раз два""два один"$$Заменяет литерал "$". \b(\d+)\s?USD$$$1"103 доллара США""103 доллара"$&Заменяет копию всего совпадения. \$?\d*\.?\d+**$&**"1,30 доллара""**1,30$**"$`Заменяет весь текст входной строки до совпадения. Б+$`"AABBCC""ААААКК"Заменяет весь текст входной строки после совпадения. Б+"AABBCC""ААККЦ"$+Заменяет последнюю захваченную группу. Б+(К+)$+"AABBCCDD""AACCDD"$_Заменяет всю входную строку. Б+$_"AABBCC""AAAABBCCCC"Опции регулярных выражений
Можно указать параметры, управляющие тем, как обработчик регулярных выражений интерпретирует шаблон регулярного выражения. Многие из этих параметров могут быть указаны либо встроенными (в шаблоне регулярного выражения), либо как одна или несколько констант RegexOptions. В этом кратком справочнике перечислены только встроенные параметры.Дополнительные сведения о встроенных параметрах и параметрах RegexOptions см. в статье Параметры регулярных выражений.
Вы можете указать встроенный параметр двумя способами:
- С помощью другой конструкции
(?imnsx-imnsx), где знак минус (-) перед параметром или набором параметров отключает эти параметры. Например,(?i-mn)включает сопоставление без учета регистра (i), выключает многострочный режим (m) и выключает захват безымянных групп (n). Параметр применяется к шаблону регулярного выражения, начиная с точки, в которой он определен, и действует либо до конца шаблона, либо до точки, где другая конструкция обращает параметр. - С помощью конструкции группировки
(?imnsx-imnsx:подвыражение), которая определяет параметры только для указанной группы.
Механизм регулярных выражений .NET поддерживает следующие встроенные параметры:
Опция Описание Узор Совпадения иИспользовать сопоставление без учета регистра. и $соответствуют началу и концу строки, а не началу и концу строки.Пример см. в разделе «Многострочный режим» раздела «Параметры регулярных выражений». нетНе захватывать безымянные группы. Пример см. в разделе «Только явные захваты» в параметрах регулярных выражений. сИспользовать однолинейный режим. Пример см. в разделе «Однострочный режим» раздела «Параметры регулярных выражений». хИгнорировать неэкранированные пробелы в шаблоне регулярного выражения. \b(?x) \d+ \s \w+"1 трубкозуб","2 кошки"в"1 трубкозуб 2 кошки IV центурионы"Разные конструкции
Разные конструкции либо изменяют шаблон регулярного выражения, либо предоставляют информацию о нем. В следующей таблице перечислены различные конструкции, поддерживаемые .СЕТЬ. Дополнительные сведения см. в разделе Разные конструкции.
Конструкция Определение Пример (?imnsx-imnsx)Задает или отключает такие параметры, как нечувствительность к регистру в середине шаблона. Дополнительные сведения см. в разделе Параметры регулярных выражений.\bA(?i)b\w+\bсоответствует"ABA","Able"в"ABA Able Act"(?#комментарий)Встроенный комментарий.Комментарий заканчивается первой закрывающей скобкой. \bA(?# Соответствует словам, начинающимся с буквы A)\w+\b#[до конца строки]Комментарий X-режима. Комментарий начинается с неэкранированного #и продолжается до конца строки.(?x)\bA\w+\b# Соответствует словам, начинающимся с AСм. также
Памятка по синтаксису регулярных выражений — JavaScript
.Имеет одно из следующих значений:
- Соответствует любому одиночному символу , кроме разделителей строк :
\n,\r,\u2028или\. Например, /.y/соответствует «мой» и «ау», а не «да», в «да, сделай мой день». - Внутри класса символов точка теряет свое особое значение и
соответствует буквальной точке.] Можно использовать — он будет соответствовать любому символу
включая новые строки.
В ES2018 добавлен флаг
s"dotAll", который позволяет точке также соответствуют терминаторам строк.
\дСоответствует любой цифре (арабской цифре). Эквивалентно
[0-9]. Например,/\d/или/[0-9]/соответствует «2» в «B2 — это номер люкса».0-9]/ соответствует «B» в «B2 — номер набора».\шСоответствует любому буквенно-цифровому символу основного латинского алфавита, включая подчеркивание.
Эквивалентно [A-Za-z0-9_]. За например,/\w/соответствует «а» в «яблоке», «5» в «5,28 доллара» и «3» в «3D».\ВтСоответствует любому символу, который не является символом слова из основного Латинский алфавит.A-Za-z0-9_]/ соответствует "%" в «50%».
Соответствует одному символу пробела, включая пробел, табуляцию, форму перевод строки, перевод строки и другие пробелы Unicode. Эквивалентно
[ \f\n\r\t\v\u00a0\u1680\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]. Например,/\s\w*/соответствует "bar" в "foo bar".\ССоответствует одному символу, кроме пробела.
\f\n\r\t\v\u00a0\u1680\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff] . Например, /\S\w*/соответствует "foo" в "foo bar".\ тСоответствует горизонтальной вкладке. Соответствует возврату каретки. \нСоответствует переводу строки. \vСоответствует вертикальной вкладке. \фСоответствует переводу страницы. [\b]Соответствует возврату. Если вы ищете символ границы слова ( \b), см. Границы.\0Соответствует символу NUL. Не используйте после этого другую цифру. \с ХСоответствует управляющему символу, используя нотация вставки, где «X» — буква от A до Z (соответствует кодовым точкам
U+0001–U+001F). Например, /\cM/соответствует "\r" в "\r\n".\x ччСоответствует символу с кодом чч(два шестнадцатеричные цифры).\и чхххСопоставляет кодовую единицу UTF-16 со значением чччч(четыре шестнадцатеричных цифры).\u {hhhh} или \u{hhhhh}(Только когда установлен флаг u.) Соответствует символу с значение ЮникодаU+ ччччилиU+ ччччч(шестнадцатеричные цифры).\Указывает, что следующий символ следует обрабатывать особым образом, или "сбежал".
Он ведет себя одним из двух способов.- Для символов, которые обычно трактуются буквально, указывает, что
следующий символ является специальным и не должен интерпретироваться буквально.Например,
/b/соответствует символу "b". Поместив обратную косую черту перед "b", то есть с помощью/\b/, символ становится специальным, чтобы означать соответствие границе слова. - Для символов, которые обычно обрабатываются особым образом, указывает, что
следующий символ не является специальным и должен быть интерпретирован
в прямом смысле. Например, «*» — это специальный символ, означающий 0 или
должно быть сопоставлено больше вхождений предшествующего символа; за
например,
/a*/означает соответствие 0 или более буквам "a".Чтобы соответствовать*буквально, поставьте перед ним обратную косую черту; Например,/a\*/соответствует "a*".
Обратите внимание, что некоторые символы, такие как
:,-,@и т. д. не имеют особого значения при экранировании или когда не сбежал. Escape-последовательности типа\:,\-,\@будут эквивалентны их литералам, неэкранированные эквиваленты символов в регулярных выражениях.Однако в регулярные выражения с unicode, это вызовет ошибку недействительной идентификации . Это сделано для обеспечения обратной совместимости с существующим кодом, использующим новые escape-последовательности, такие как\pили\k.Примечание: Чтобы буквально сопоставить этот символ, экранируйте его. с собой. Другими словами, для поиска
\используйте/\\/.1. Что такое регулярное выражение?
Регулярные выражения представляют собой специально закодированные текстовые строки, используемые как шаблоны для сопоставления наборов строк. Они начали появляться в 1940-х гг. способ описания обычных языков, но они действительно начали появляться в мир программирования в 1970-х годах. Первое я мог найти их в текстовом редакторе QED, написанном Кеном Томпсоном.
«Регулярное выражение — это шаблон, который определяет набор строк персонажей; говорят, что он соответствует определенным строкам.” —Кен Томпсон
Регулярные выражения позже стали важной частью набора инструментов который появился из операционной системы Unix — ed , с и с ( vim ) редакторы, grep , AWK и др. Но способы, которыми регулярно выражения были реализованы не всегда так регулярно.
Примечание
В этой книге используется индуктивный подход; другими словами, он движется от частного к общему.
\d{3}[.-]?)?\d{3}[.-]?\d{4}$ , к чему мы и подойдем в конце этой главы: надежное регулярное выражение, соответствующее 10-значному номеру телефона в Северной Америке номер, с кодом города в скобках или без них, с кодом города или без него дефисы или точки (точки) для разделения чисел. (круглые скобки должны быть тоже сбалансированный; другими словами, вы не можете просто иметь один.)
Примечание
Глава 10 показывает вам немного более сложный регулярное выражение для номера телефона, но приведенного выше достаточно для цели настоящей главы.
Если вы еще не поняли, как все это работает, не беспокойтесь: я объясню все выражение понемногу в этой главе. Если вы просто будете следовать примеры (и, если уж на то пошло, по всей книге), написание регулярные выражения скоро станут для вас второй натурой. Готов узнать для себя?
Иногда я представляю символы Unicode в этой книге, используя их кодовая точка — четырехзначное шестнадцатеричное (с основанием 16) число.
Эти
кодовые точки отображаются в виде U+0000 .U+002E, для
например, представляет кодовую точку для точки или точки (.).Сначала позвольте представить вам веб-сайт Regexpal по адресу http://www.regexpal.com. Откройте сайт в браузере, например Google Chrome или Mozilla Firefox. Вы можете увидеть, как выглядит сайт как на рис. 1-1.
Рис. 1-1. Regexpal в браузере Google Chrome
Вы можете видеть, что в верхней части есть текстовая область, а большая текстовое поле под ним. Верхнее текстовое поле предназначено для ввода обычного выражения, а нижний содержит тему или целевой текст.То целевой текст — это текст или набор строк, которые вы хотите сопоставить.
Примечание
В конце этой и каждой последующей главы вы найдете раздел «Технические примечания». Эти примечания содержат дополнительную информацию о технологии, рассмотренной в главе, и рассказать, где взять больше информации об этой технологии.
Размещение этих заметок в конце
глав помогает поддерживать поток основного текста в движении вперед
вместо того, чтобы останавливаться, чтобы обсудить каждую деталь по пути.Теперь мы сопоставим номер телефона в Северной Америке с регулярным выражением. Тип указанный здесь номер телефона в нижней части Regexpal:
707-827-7019
Узнаете ли вы его? Это номер O’Reilly Media.
Сопоставим это число с регулярным выражением. Есть много способов сделать это, но для начала просто введите сам номер в поле верхний раздел, точно так же, как написано в нижнем разделе (подожди сейчас, не вздыхайте):
707-827-7019
Вы должны увидеть номер телефона, который вы ввели в нижнее поле выделены от начала до конца желтым цветом.Если это то, что вы видите (как показано на рис. 1–2), то вы в деле.
Примечание
Когда я упоминаю цвета в этой книге в связи с чем-то, что вы можно увидеть на изображении или снимке экрана, например выделение в Regexpal, эти цвета могут отображаться в Интернете и в версиях электронных книг.
книга, но, увы, не в печати. Итак, если вы читаете эту книгу на бумаге,
тогда, когда я упомяну цвет, ваш мир будет в оттенках серого, с моим
извинения.Рис. 1-2.Десятизначный номер телефона, выделенный в Regexpal
В этом регулярном выражении вы использовали что-то вызывает строковый литерал для соответствия строке в целевом тексте. Строковый литерал — это буквальное представление строки.
Теперь удалите число в верхнем поле и замените его только номер 7 . Вы видели, что произошло? Теперь только выделены семерки. Буквенный символ (число) 7 в регулярном выражении соответствует четырем экземпляры числа 7 в тексте, который вы сопоставляете.
Что, если вы хотите сопоставить все цифры в телефонном номере сразу? Или соответствует любому номеру в этом отношении?
Попробуйте следующее, точно так же, как показано, еще раз в верхнем тексте поле:
[0-9]
Все числа (точнее цифр ) в нижняя часть выделена чередующимся желтым и синим цветом.
Что за
регулярное выражение [0-9]говорит процессор регулярных выражений: «Сопоставьте любую цифру, которую вы найдете в диапазоне от 0 до 9.”Квадратные скобки не совпадают буквально, потому что они обрабатывается специально как метасимволов . Метасимвол имеет особое значение в регулярных выражениях и зарезервировано. Обычный выражение в форме
[0-9]называется классом символов или иногда набором символов .Можно точнее ограничить диапазон цифр и получить то же самое результат, используя более конкретный список цифр для сопоставления, например следующим образом:
[012789]
Это будет соответствовать только перечисленным цифрам, то есть 0, 1, 2, 7, 8, и 9.Попробуйте в верхнем поле. Еще раз, каждая цифра в нижнем поле будут выделены чередующимися цветами.
Для соответствия любому 10-значному номеру телефона в Северной Америке, части которого разделенные дефисом, вы можете сделать следующее:
[0-9][0-9][0-9]-[0-9][0-9][0-9]-[0-9][ 0-9][0-9][0-9]
Это сработает, но это напыщенно.
Есть лучший способ с
нечто, называемое стенографией.Еще один способ сопоставления цифр, который вы видели в начале глава содержит
\d, что само по себе будет соответствовать всем арабским цифрам, как и[0-9].Попробуйте это в верхней части и, как и в предыдущих регулярных выражениях, цифры ниже будут выделено. Такое регулярное выражение называется символов сокращение . (Его также называют экранированием символов , но это термин может ввести в заблуждение, поэтому я его избегаю. Я объясню позже.)Чтобы сопоставить любую цифру в телефонном номере, вы также можете сделать это:
\d\d\d-\d\d\d-\d\d\d\d
Повторение
\dтри и четыре раз в последовательности будет точно соответствовать трем и четырем цифрам в последовательности.Дефис в приведенном выше регулярном выражении вводится как литерал символ и будет соответствовать как таковой.Что насчет дефисов? Как вы их сопоставляете? Вы можете использовать буквальный дефис (-), как уже показано, или вы можете использовать экранированный верхний регистр D (
\D), который соответствует любому символу, который равен , а не a цифра.В этом образце используется
\Dвместо буквальный дефис.\d\d\d\D\d\d\d\D\d\d\d\d
Опять же, весь номер телефона, включая дефисы, должен выделиться на этот раз.
Вы также можете сопоставить эти надоедливые дефисы с точкой (.):
\d\d\d.\d\d\d.\d\d\d\d
Точка или точка по существу действуют как подстановочный знак и будет соответствовать любому символ (кроме, в некоторых случаях, конца строки). В примере выше регулярное выражение соответствует дефису, но оно также может соответствовать знак процента (%):
707%827%7019
Или вертикальная черта (|):
707|827|7019
Или любой другой символ.
Примечание
Как я уже говорил, точка (официально точка) обычно не соответствует символу новой строки, например переводу строки (U+000A).Однако есть способы сделать возможным сопоставление новой строки с точка, которую я покажу вам позже. Это часто называют довсего варианта .
Теперь вы сопоставите только часть телефонного номера, используя то, что известная как группа захвата . Затем вы обратитесь к содержимое группы с обратной ссылкой . Чтобы создать захват группу, в пару
\dвложить скобки, чтобы поместить его в группу, а затем\1для обратной ссылки на то, что было захвачено:(\d)\d\1
заключены в группу, заключенную в круглые скобки.В результате это регулярное выражение соответствует префикс
707. Вот разбивка это:(\d)соответствует первой цифре и фиксирует его (число 7 )\dсоответствует следующей цифре (число 0 ), но не фиксирует его, потому что он не заключен в круглые скобки\1ссылки на захваченные цифра (число 7 )
Это будет соответствовать только коду города.
Не волнуйтесь, если вы не полностью
поймите это прямо сейчас. Позже вы увидите множество примеров групп.
в книге.Теперь вы можете сопоставить весь номер телефона с одной группой и несколько обратных ссылок:
(\d)0\1\D\d\d\1\D\1\d\d\d
Но это не так элегантно, как могло бы быть. Давайте попробуем что-нибудь это работает еще лучше.
Вот еще один способ сопоставить номер телефона, используя другой синтаксис:
\d{3}-?\d{3}-?\d{4}Числа в фигурных скобках сообщают обработчику регулярных выражений ровно сколько вхождений этих цифр вы хотите это искать.Скобки с числами являются своего рода квантификатором . Сами брекеты считаются метасимволами.
Вопросительный знак (
?) другой вид квантификатора. Он следует за дефисом в регулярное выражение выше и означает, что дефис необязателен, т. е. что может быть ноль или одно вхождение дефиса (один или ни одного). Есть и другие квантификаторы, такие как знак плюс (+), который означает «один или несколько», или звездочка (*), что означает «ноль или более».Используя квантификаторы, вы можете сделать регулярное выражение еще более кратко:
(\d{3,4}[.-]?)+Знак плюс снова означает, что количество может встречаться один или несколько раз. Это регулярное выражение будет соответствовать трем или четырем цифрам, за которым следует необязательный дефис или точка, сгруппированные скобками, один или несколько раз (
+).Голова кружится? Надеюсь нет. Вот посимвольно анализ регулярного выражения выше:
(открыть захват группа\начальный символ сокращение (экранирование следующего символа)dсокращение для конечного символа (любая цифра в диапазоне от 0 до 9 соответствует\d){квантификатор открытия3минимальное количество для,отдельные количества4максимальное количество до match}закрытый квантификатор[открытый класс символов.точек или точек (соответствует буквенная точка) -буквальный символ для соответствия дефис]близкий символ класс?ноль или единица квантификатор)близкий захват группа+один или несколько квантификатор
Все это работает, но не совсем правильно, потому что тоже совпадет другие группы из 3 или 4 цифр, будь то в виде номера телефона или нет.Да, мы учимся на своих ошибках лучше, чем на своих успехах.
Итак, давайте немного улучшим его:
(\d{3}[.-]?){2}\d{4}Это будет соответствовать двум последовательностям, не заключенным в скобки, по три цифры в каждой, за которым следует необязательный дефис, а затем ровно четыре цифры.
Наконец, вот регулярное выражение, позволяющее использовать круглые скобки опционально обернуть первую последовательность из трех цифр и сделать область также необязательный код:
^(\(\d{3}\)|^\d{3}[. (знак знака вставки) в начале регулярного выражения или после
вертикальная черта ( |) означает, что номер телефона будет в начале строки. -
(открывает захват группа. -
\(- буквальный открытый скобка. -
\dсоответствует цифре. -
{3}- квантификатор, который, после\dсоответствует ровно трем цифры. соответствует началу линия. -
\dсоответствует цифре. -
{3}является квантификатором который соответствует ровно трем цифрам. -
[.-]?соответствует необязательной точке или дефис. -
)Группа ближнего захвата. -
?сделать группу необязательной, то есть префикс в группе не обязательный. -
\dсоответствует цифре. -
{3}соответствует ровно трем цифры. -
[.-]?соответствует другому необязательная точка или дефис. -
\dсоответствует цифре. -
{4}соответствует ровно четырем цифры. -
$соответствует концу строки. -
Что такое регулярное выражение
-
Как использовать Regexpal, простое регулярное выражение процессор
-
Как сопоставить строковые литералы
-
Как сопоставить цифры с классом символов
-
Как сопоставить цифру с сокращенным символом
-
Как сопоставить цифру с символом
-
Как использовать группу захвата и обратную ссылку
-
Как сопоставить точное количество набора строк
-
Как сопоставить необязательно символ (ноль или один) или один или несколько раз
-
Как сопоставить строки в начале или в конце линия
-
Regexpal (http://www.
regexpal.com) является
веб-реализация регулярных выражений на основе JavaScript. Его
не самая полная реализация, да и не все умеет
что могут делать регулярные выражения; тем не менее, это чистый, простой и
очень простой в использовании инструмент обучения, и он предоставляет множество функций для
вы, чтобы начать. -
Браузер Chrome можно загрузить с https://www.google.com/chrome или Firefox с http://www.mozilla.org/en-US/firefox/new/.
-
Почему существует так много способов сделать что-то с обычными выражения? Одна из причин заключается в том, что регулярные выражения имеют замечательное качество называется компонуемость .Язык, будь то формальный язык программирования или схемы, обладающий качеством компонуемость (Джеймс Кларк хорошо объясняет это на http://www.thaiopensource.com/relaxng/design.html#section:5) это тот, который позволяет вам взять его атомарные части и методы композиции и затем легко рекомбинировать их по-разному.
Как только вы изучите
различные части регулярных выражений, которые вы будете использовать в своих
способность сопоставлять строки любого типа. -
TextMate доступен на http://www.www.macromates.com. Для получения дополнительной информации о регулярные выражения в TextMate, см. http://manual.macromates.com/en/regular_expressions.
-
Дополнительную информацию о блокноте см. по адресу http://notepad-plus-plus.org. Для документации по использование регулярных выражений в Блокноте, см. http://sourceforge.net/apps/mediawiki/notepad-plus/index.php?title=Regular_Expressions.
-
Узнайте больше о Oxygen на http://www.oxygenxml.com. Для получения информации об использовании регулярное выражение через поиск и замену, см. http://www.а...с$
абсНет соответствия псевдонимСовпадение безднаСовпадение ПсевдонимНет соответствия СчетыНет соответствия
Python имеет модуль с именем
reдля работы с RegEx. а...s$'
test_string = 'бездна'
результат = re.match (шаблон, тестовая_строка)
если результат:
print("Поиск успешен.")
еще:
print("Поиск не удался.")
Здесь мы использовали функцию
re.match()для поиска шаблона в пределах test_string . Метод возвращает объект соответствия, если поиск успешен. Если нет, возвращаетсяNone.В модуле re определено несколько других функций для работы с RegEx. $ * + ? {} () \ |
[]- Квадратные скобкиКвадратные скобки определяют набор символов, которые вы хотите сопоставить.
Выражение Строка Совпало? [абв]и1 совпадение переменный ток2 совпадения Эй, ДжудНет соответствия абв де ка5 совпадений Здесь
[abc]будет соответствовать, если строка, которую вы пытаетесь сопоставить, содержит любой изa,bилиc. используется для проверки того, начинается ли строка с определенного символа.аб абв1 совпадение акбНет совпадения (начинается с a, но не сопровождаетсяb)$- ДолларСимвол доллара
$используется для проверки того, заканчивается ли строка на определенным символом.Выражение Строка Совпало? $и1 совпадение формула1 совпадение кабинаНет соответствия *- ЗвездаСимвол звезды
*соответствует нулю или большему количеству вхождений шаблона, оставленного ему.Выражение Строка Совпало? основноймин1 совпадение мужчина1 совпадение маан1 совпадение основнойНет совпадений (за ине следуетn)женщина1 совпадение +- ПлюсСимвол "плюс"
+соответствует одному или нескольким вхождениям оставшегося шаблона.Выражение Строка Совпало? ма+нминНет соответствия (отсутствие символа)мужчина1 совпадение маан1 совпадение основнойНет совпадений (за a не следует n) женщина1 совпадение ?- Знак вопросаЗнак вопроса
?соответствует нулю или одному вхождению оставшегося шаблона.Выражение Строка Совпало? основноймин1 совпадение мужчина1 совпадение маанНет совпадения (более одного символа и)основнойНет совпадений (за a не следует n) женщина1 совпадение {}- РаспоркиРассмотрим этот код:
{n,m}.Это означает, что ему осталось не менее n и не более m повторений паттерна.Выражение Строка Совпало? а{2,3}абв датНет соответствия абв даат1 спичка ( д аа т)аабв дааат2 спички (at aa bcиd aaa t)аабв даааат2 спички (at aa bcиd aaa at)Давайте попробуем еще один пример.
Это регулярное выражение [0-9]{2, 4}соответствует как минимум 2 цифрам, но не более 4 цифрамВыражение Строка Совпало? [0-9]{2,4}ab123csde1 совпадение (совпадение по адресу ab 123 csde)12 и 3456733 спички ( 12,3456,73)1 и 2Нет соответствия |- АльтернативаВертикальная перекладина
|используется для чередования (операторили).Выражение Строка Совпало? а|бкодНет соответствия аде1 совпадение (совпадение по и по)акдбеа3 спички (at a cd b e a)Здесь
a|bсоответствует любой строке, которая содержит a или b()- ГруппаСкобки
.()используется для группировки подшаблонов. Например, (a|b|c)xzсоответствует любой строке, которая соответствует либо a , либо b , либо c , за которыми следует xzВыражение Строка Совпало? (a|b|c)xzаб хзНет соответствия абхз1 совпадение (соответствие a bxz)аксз кабксз2 совпадения (at axz bc ca bxz)\- Обратная косая чертаBacklash
\используется для экранирования различных символов, включая все метасимволы.Например,\$соответствует, если строка содержит$, за которыми следуетa. Здесь $не интерпретируется движком RegEx особым образом.Если вы не уверены, имеет ли символ особое значение или нет, вы можете поставить перед ним
\. Это гарантирует, что с персонажем не обращаются особым образом.Специальные последовательности
Специальные последовательности упрощают запись часто используемых шаблонов.Вот список специальных последовательностей:
\A— Соответствует, если указанные символы находятся в начале строки.Выражение Строка Совпало? \AtheсолнцеСовпадение На солнцеНет соответствия \b— Соответствует, если указанные символы находятся в начале или в конце слова.Выражение Строка Совпало? \bfooфутболСовпадение футбольный мячСовпадение футболНет соответствия foo\bфуСовпадение тест афуСовпадение самый нижнийНет соответствия \B- Напротив\b.Соответствует, если указанные символы равны , а не в начале или конце слова.Выражение Строка Совпало? \BfooфутболНет соответствия футбольный мячНет соответствия футболСовпадение foo\BфуНет соответствия тест афуНет соответствия самый нижнийСовпадение \d— соответствует любой десятичной цифре. 0-9] Выражение Строка Совпало? \Д1ab34"503 спички (по 1 аб 34 " 50)1345Нет соответствия \s— Соответствует, если строка содержит любой символ пробела.Эквивалентно[ \t\n\r\f\v].Выражение Строка Совпало? Регулярное выражение Python1 совпадение PythonRegExНет соответствия \S— Соответствует, если строка содержит любой непробельный символ. \t\n\r\f\v] .Выражение Строка Совпало? \Са б2 спички (по а б)Нет соответствия \w— соответствует любому буквенно-цифровому символу (цифры и буквы). Эквивалент[a-zA-Z0-9_].Кстати, подчеркивание_тоже считается буквенно-цифровым символом.Выражение Строка Совпало? \ш12 дюймов ;с3 совпадения (в 12 &": ; c)%"> !Нет соответствия \W— соответствует любому небуквенно-цифровому символу. a-zA-Z0-9_] Выражение Строка Совпало? \Вт1a2%c1 совпадение (при 1 a 2 % c)ПитонНет соответствия \Z— Соответствует, если указанные символы находятся в конце строки.Выражение Строка Совпало? Python\ZМне нравится Python1 совпадение Мне нравится программировать на PythonНет соответствия Python — это весело. Нет соответствия Совет: Для создания и тестирования регулярных выражений можно использовать инструменты проверки регулярных выражений, такие как regex101. Этот инструмент не только поможет вам в создании регулярных выражений, но и поможет вам изучить их.
Теперь вы понимаете основы RegEx, давайте обсудим, как использовать RegEx в вашем коде Python.
Регулярное выражение Python
Python имеет модуль с именем
reдля работы с регулярными выражениями.Чтобы использовать его, нам нужно импортировать модуль.импортныйМодуль определяет несколько функций и констант для работы с RegEx.
re.findall()
Метод
re.findall()возвращает список строк, содержащих все совпадения.Пример 1: re.findall()
# Программа для извлечения чисел из строки импортировать повторно строка = 'привет 12 привет 89. Привет 34'
шаблон = '\d+'
результат = re.findall (шаблон, строка)
печать (результат)
# Вывод: ['12', '89', '34']
Если шаблон не найден,
повтор.findall()возвращает пустой список.re.split()
Метод
re.splitразделяет строку, в которой есть совпадение, и возвращает список строк, в которых произошло разделение.Пример 2: re.split()
импортировать повторно строка = 'Двенадцать:12 восемьдесят девять:89.' шаблон = '\d+' результат = re.split (шаблон, строка) печать (результат) # Вывод: ['Двенадцать:', ' Восемьдесят девять:', '.']Если шаблон не найден,
повтор.split()возвращает список, содержащий исходную строку.Вы можете передать аргумент
maxsplitметодуre.split(). Это максимальное количество расщеплений, которое может произойти.импортировать повторно string = 'Двенадцать:12 Восемьдесят девять:89 Девять:9. '
шаблон = '\d+'
# макссплит = 1
# разбить только при первом вхождении
результат = re.split (шаблон, строка, 1)
печать (результат)
# Вывод: ['Двенадцать:', ' Восемьдесят девять:89 Девять:9.']
Кстати, значение по умолчанию
maxsplitравно 0; что означает все возможные расщепления.re.sub()
Синтаксис
re.sub():re.sub(шаблон, замена, строка)Метод возвращает строку, в которой совпадающие вхождения заменены содержимым переменной replace .
Пример 3: re.sub()
# Программа для удаления всех пробелов импортировать повторно # многострочная строка строка = 'абв 12\ де 23 \н ф45 6' # соответствует всем пробельным символам шаблон = '\s+' # пустой строки заменить = '' новая_строка = повторно.sub(шаблон, замена, строка) печать (новая_строка) # Вывод: abc12de23f456Если шаблон не найден,
re.sub()возвращает исходную строку.Вы можете передать count в качестве четвертого параметра в метод
re.sub(). Если его опустить, результатом будет 0. Это заменит все вхождения.импортировать повторно # многострочная строка строка = 'абв 12\ де 23 \н ф45 6' # соответствует всем пробельным символам шаблон = '\s+' заменить = '' новая_строка = повторно.sub(r'\s+', заменить, строка, 1) печать (новая_строка) # Вывод: # abc12de 23 # ф45 6re.subn()
re.subn()аналогиченre.sub(), за исключением того, что он возвращает кортеж из 2 элементов, содержащих новую строку и количество сделанных замен.Пример 4: re.subn()
# Программа для удаления всех пробелов импортировать повторно # многострочная строка строка = 'абв 12\ де 23 \н ф45 6' # соответствует всем пробельным символам шаблон = '\s+' # пустой строки заменить = '' новая_строка = повторно.subn(шаблон, замена, строка) печать (новая_строка) # Вывод: ('abc12de23f456', 4)поиск()
Метод
re.принимает два аргумента: шаблон и строку. Метод ищет первое место, где шаблон RegEx создает совпадение со строкой. search() Если поиск успешен,
re.search()возвращает объект соответствия; если нет, возвращаетсяNone.совпадение = поиск (шаблон, строка)Пример 5: пере.поиск()
импортировать повторно string = "Питон - это весело" # проверить, стоит ли 'Python' в начале match = re.search('\APython', строка) если совпадают: print("Шаблон найден внутри строки") еще: print("шаблон не найден") # Вывод: шаблон найден внутри строкиЗдесь match содержит объект match.
Спичечный предмет
Вы можете получить методы и атрибуты объекта соответствия, используя функцию dir().
Некоторые из часто используемых методов и атрибутов объектов соответствия:
совпадение.группа()
Метод
group()возвращает часть строки, в которой есть совпадение.Пример 6: Соответствие объекту
импортировать повторно строка = '39801 356, 2102 1111' # Трехзначное число, за которым следует пробел, за которым следует двузначное число шаблон = '(\d{3}) (\d{2})' # переменная match содержит объект Match. match = re.search(шаблон, строка) если совпадают: печать (совпадение.группа()) еще: print("шаблон не найден") # Вывод: 801 35Здесь match переменная содержит объект match.
Наш шаблон
(\d{3}) (\d{2})имеет две подгруппы(\d{3})и(\d{2}). Вы можете получить часть строки этих подгрупп в скобках. Вот как:>>> match.group(1) «801» >>> match.group(2) '35' >>> match.group(1, 2) («801», «35») >>> match.groups() («801», «35»)match.start(), match.end() и match.span()
Функция
start()возвращает индекс начала совпадающей подстроки.Аналогично,end()возвращает конечный индекс совпадающей подстроки.>>> match.start() 2 >>> match.end() 8Функция
span()возвращает кортеж, содержащий начальный и конечный индексы совпадающей части.>>> match.span() (2, 8)match.re и match.string
Атрибут
reсовпадающего объекта возвращает объект регулярного выражения. Точно так же атрибутstringвозвращает переданную строку.>>> match.re re.compile('(\\d{3}) (\\d{2})') >>> match.string '39801 356, 2102 1111'Мы рассмотрели все часто используемые методы, определенные в модуле
re. Если вы хотите узнать больше, посетите модуль Python 3 re.Использование префикса r перед RegEx
Когда префикс r или R используется перед регулярным выражением, это означает необработанную строку. Например,
'\n'— это новая строка, тогда какr'\n'означает два символа: обратную косую черту\, за которой следуетn.Backlash
\используется для экранирования различных символов, включая все метасимволы. Однако использование префикса r приводит к тому, что\рассматривается как обычный символ.Пример 7. Необработанная строка с префиксом r
импортировать повторно string = '\n и \r являются управляющими последовательностями.' результат = re.findall(r'[\n\r]', строка) печать (результат) # Вывод: ['\n', '\r']Функция REGEXREPLACE( )
Заменяет все экземпляры строк, соответствующие регулярному выражению с новым нить.
Синтаксис
REGEXREPLACE(строка, шаблон, новая_строка)
Параметры
Имя Тип Описание струна символ
Поле, выражение или литеральное значение для проверки для соответствующего шаблона. узор символ
Строка шаблона (регулярное выражение) для поиска.
Шаблонможет содержать буквенные символы, метасимволы или их комбинация. Буквенные символы включать все буквенно-цифровые символы, некоторые знаки пунктуации, и пробелы.
Поиск чувствителен к регистру, что означает, что прописные и строчные буквы должны быть указаны явно.
новая_строка символ Строка, используемая для замены всех значений, соответствующих шаблону.
Строка замены может содержать буквенные символы, группы символы из исходной строки (с помощью элемента $int), или их комбинация.
Примеры
Основные примеры
Работа с пробелами
Возвращает "AB CD EF", заменяя несколько пробелов между текстовыми символами одним пробелом:
REGEXREPLACE("AB CD EF", "\s+", " ")Возвращает данные символьного поля с интервал между словами стандартизирован на один пробел:
REGEXREPLACE(character_field, "\s+", " ")
Возвращает данные символьного поля с интервал между словами стандартизирован на один пробел.
С использованием
функцию BLANKS( ) в new_string, а не
чем буквенный пробел, делает пробелы более легкими для чтения и менее вероятными
игнорировать:REGEXREPLACE(character_field, "\s+", BLANKS(1))
Стандартизация телефонных номеров
Возвращает "(123) 456-7890". Форматирование номер телефона '1234567890' стандартизирован:
REGEXREPLACE(SUBSTR("1234567890",1,14), "(\d{3})[\s-]*(\d{3})[\s-]* (\d{4})","($1) $2-$3")Возвращает номера в Telephone_Number поле и стандартизирует их форматирование:
REGEXREPLACE(номер_телефона, ".*(\d{3})[\s-\.\)]*(\d{3})[\s-\.]*(\d{4})", "($1) $2-$3" )Выписка "123-456-7890" из окружающего текст:
REGEXREPLACE("Тел. номер: 123-456-7890 (офис)", "(.*)(\d{3}[\s-\)\. ]*\d{3}[\s- \.]*\d{4})(.*)", "$2") Извлекает телефонные номера из окружающих текст в поле Комментарий и стандартизирует их форматирование:
REGEXREPLACE(Комментарий, "(.*)(\d{3})[\s-\)\.]*(\d{3})[\s-\.]*(\d{4})(.*)","($2 ) $3-$4")Определение общих форматов
Возвращает "9XXX-999xx", который представляет общий формат значения, заданного строкой ("1ABC-123aa"):
REGEXREPLACE(REGEXREPLACE(REGEXREPLACE("1ABC-123aa","\d","9") ,"[az]","x"),"[AZ]", "X")Возвращает общий формат всех идентификаторов в поле Invoice_Number:
REGEXREPLACE(REGEXREPLACE(REGEXREPLACE(Invoice_Number,"\d","9"),"[a-z]","x"),"[A-Z]", "X")
Стандартизация формата имени
Возвращает "Джон Дэвид Смит":
REGEXREPLACE("Смит, Джон Дэвид", "^(\w+),(\s\w+)(\s\w+)?(\s\w+)?","$2 $3$4 $1")Возвращает имена в поле Full_Name в обычном порядке: первый (средний) (Средний) Последний:
REGEXREPLACE(Full_Name, "^(\w+),(\s\w+)(\s\w+)?(\s\w+)?","$2$3$4 $1")
Примечание
Данные имени могут представлять различные сложности, такие как апострофы.
в именах.Учет вариаций в данных об именах обычно требует больше
сложные регулярные выражения, чем в приведенном выше примере.Удаление разметки HTML
Возвращает "https://www.flgov.com/wp-content/uploads/orders/2020/EO_20-166.pdf":
REGEXREPLACE("Замечания
Как это работает
Функция REGEXREPLACE() использует регулярное выражение для поиска совпадающих шаблонов. в данных и заменяет любые совпадающие значения новой строкой.
Для пример:
REGEXREPLACE(character_field, "\s+", " ")
стандартизирует пробелы в символах данные, заменив один или несколько пробелов между текстовыми символами на единое пространство.
Часть поиска REGEXREPLACE() идентична функции REGEXFIND(). За подробная информация о возможностях поиска, общих для обоих функции, см. функцию REGEXFIND().
Когда использовать REGEXREPLACE()
Используйте REGEXREPLACE() каждый раз, когда вам нужно найти и заменить данные в Google Analytics с помощью простого или сложного сопоставления с образцом.
Замена символов на себя
Вы можете использовать элемент $int заменять символы на себя, что позволяет сохранить значимые части данных, стандартизируя или опуская окружающие или смешанные данные.
Несколько примеров с использованием телефонных номеров и имена появляются выше.
Чтобы использовать элемент $int сначала необходимо создать группы, используя круглые скобки ( ) в значении шаблона. Дополнительные сведения см. в разделе Функция REGEXFIND().
Избегание последовательного символа соответствие
Вы можете избежать последовательного символа соответствия и заменять подстроки независимо от их положения в относительно друг друга, путем вложения функций REGEXREPLACE().
Проблема в двух приведенных ниже примерах заключается в получении универсального формата из буквенно-цифровых исходных данных, в которых числа и буквы могут появляться в любом порядке. Как построить строку шаблона, не зная порядка цифр и букв?
Решение состоит в том, чтобы сначала найти и заменить числа с помощью внутренней функции REGEXREPLACE(), а затем найти и заменить буквы с помощью внешней функции REGEXREPLACE().
Возвращает "999XXX":
REGEXREPLACE(REGEXREPLACE("123ABC","\d","9"),"[A-Z]","X")Возвращает "9X9X9X":
REGEXREPLACE(REGEXREPLACE("1A2B3C","\d","9")","[A-Z]","X")Сменная длина строки и усечение
При использовании REGEXREPLACE() для создания вычисляемого поля длина вычисляемого поля идентична к исходной длине поля.
Если длина строки замены превышает длина целевой строки, общая длина строки увеличивается, что приводит к в усечении, если вычисляемая длина поля не может вместить увеличенное длина строки.
Символы, следующие за целевой строкой, усекаются сначала, за которым следуют символы строки замены.
Примеры
ниже показано усечение:строка
узор
новая_строка
Длина поля
Результат
Усеченные символы х 123 х
123
А
5
"хАх"
нет х 123 х
123
Азбука
5
"xABCx"
нет х 123 х
123
АВСD
5
"xABCD"
"х" х 123 х
123
АВСДЕ
5
"xABCD"
"х", "Е" х 123 х
123
АВСДЕ
6
"xABCDE"
"х" х 123 х
123
АВСДЕ
7
"xABCDEx"
нет Как избежать усечения
Чтобы избежать усечения, используйте функцию SUBSTR().
для увеличения длины поля, как показано во втором примере ниже.Возвращает "xABCD", который усекает символ замены "E" и существующий символ "x":
REGEXREPLACE("x123x","123","ABCDE")Возвращает "xABCDEx", который включает все символы замены и незамещенные существующие символы:
REGEXREPLACE(SUBSTR("x123x",1,10),"123","ABCDE")Метасимволы регулярных выражений
В таблице ниже перечислены метасимволы, которые можно использовать с REGEXFIND() и REGEXREPLACE(), и описаны операция, которую выполняет каждый из них.
Дополнительное регулярное выражение синтаксис существует и поддерживается Google Analytics, но он сложнее. Полное объяснение дополнительного синтаксиса выходит за рамки охват этого руководства.
Многочисленные ресурсы, объясняющие регулярные выражения
доступны в Интернете.Analytics использует реализацию ECMAScript . регулярных выражений.Большинство реализаций регулярных выражений использовать общий синтаксис ядра.
Примечание
Текущая реализация регулярных выражений в Analytics не полностью поддерживает поиск языков, кроме английского.
Метасимвол
Описание
.
Соответствует любому символу (кроме новой строки). символ)
?
Соответствует 0 или 1 вхождению немедленного предшествующий литерал, метасимвол или элемент
*
Соответствует 0 или более вхождениям немедленно предшествующий литерал, метасимвол или элемент
+
Соответствует 1 или более вхождениям немедленно предшествующий литерал, метасимвол или элемент
{}
Соответствует указанному количеству вхождений непосредственно предшествующего литерала, метасимвола или элемента.
Вы можете указать точное число, диапазон или открытый диапазон.Для пример:
a{3} соответствует "aaa"
X{0,2}L соответствует "L", "XL" и "XXL"
AB-\d{2,}-YZ соответствует любому буквенно-цифровому идентификатору с префикс «AB-», суффикс «-YZ» и два или более числа в тело идентификатора
[]
Соответствует любому одиночному символу внутри кронштейны
Например:
[aeiou] совпадений a, или e, или i, или o, или u
[^aeiou] соответствует любому символу, отличному от a или e, или я, или о, или ты
[A-G] соответствует любой прописной букве от A до G
[A-Ga-g] соответствует любой прописной букве от A до G, или любую строчную букву от a до g
[5-9] соответствует любому числу от 5 до 9
()
Создает группу, определяющую последовательность или блок символов, который затем можно рассматривать как единое целое.
Для пример:
S(ch)?mid?th? спичек "Смит" или "Шмидт"
(56А.*){2} соответствует любому буквенно-цифровому идентификатору в в котором последовательность "56A" встречается не менее двух раз
(56A).*-.*\1 соответствует любому буквенно-цифровому идентификатору в в котором последовательность «56A» встречается не менее двух раз с дефисом, расположенным между двумя событиями
\
Управляющий символ, указывающий, что следующий за ним символ является литералом.
$ . * + ? знак равно : | \ ( ) [ ] { } Другое знаки препинания, такие как амперсанд (&) или 'at sign' (@) не требует escape-символа.
\инт
Указывает, что ранее определенная группа со скобками ( ) , повторяется.интервал целое число, определяющее порядковую позицию предыдущего определенной группы по отношению к любым другим группам.
Этот метасимвол
может использоваться в параметре шаблона в обоих
REGEXFIND() и REGEXREPLACE().Например:
(123).(\D)(\d)-.*\2\1 соответствует любому идентификатору, в котором буквенно-цифровой префикс повторяется с буквенными и цифровыми символами перевернутый
$инт
Указывает, что группа найдена в целевом строка используется в замещающей строке.
интервал
целое число, определяющее порядковую позицию группы
в целевой строке по отношению к любым другим группам. Этот метасимвол
может использоваться только в параметре new_string
в REGEXREPLACE().Например:
Если шаблон (\d{3})[ -]?(\d{3})[ -]?(\d{4}) используется для сопоставления множество различных форматов телефонных номеров, new_string ($1)-$2-$3 может использовать для замены чисел самими собой и стандартизировать форматирование.999 123-4567 и 99567 становятся (999)-123-4567.
|
Соответствует символу, блоку символов, или выражение до или после вертикальной черты ( | )
Например:
a|b соответствует a или b
abc|def соответствует "abc" или "def"
Sm(i|y)th соответствует Смиту или Смиту
[a-c]|[Q-S]|[x-z] соответствует любой из следующих букв: а, б, в, Q, R, S, x, y, z
\s|- соответствует пробелу или дефису
\ш
Соответствует любому символу слова (от a до z, от A до Z, от 0 до 9 и символ подчеркивания _ )
\Вт
Соответствует любому символу, не являющемуся словом (не z, от A до Z, от 0 до 9 или символ подчеркивания _ )
\д
Соответствует любому числу (любой десятичной цифре)
\D
Соответствует любому нечисловому (любому символу, не является десятичной цифрой)
\с
Соответствует пробелу (пробелу)
\S
Соответствует любому не пробелу (не пробелу)
\б
Соответствует границе слова (между \w и \W символов)
Границы слов сами по себе не занимают места.
Например:"United Equipment" содержит 4 границ слова - по одному с каждой стороны пространства и по одному в начале и в конце строки. «United Equipment» соответствует регулярному выражению \b\w*\b\W\b\w*\b
Наконечник
Помимо пробелов, границы слов могут возникать из-за запятых, точек и других символов, не являющихся словами.
Например, следующее выражение оценивается как True:
REGEXFIND("jsmith@example. отрицает содержимое$
Соответствует концу строки
Сопутствующие функции
Если вы хотите найти совпадающие шаблоны, не заменяя их, используйте функцию REGEXFIND().
.

 Давайте проверим.
Давайте проверим. ’ и ‘$’, которые обозначают начало и конец строк соответственно.
’ и ‘$’, которые обозначают начало и конец строк соответственно.  Я объясню шаблон после того, как вы увидите вывод:
Я объясню шаблон после того, как вы увидите вывод: ‘\\d{3}’ означает три цифры.
‘\\d{3}’ означает три цифры. ]\\d{3}[-.]\\d{4}")
]\\d{3}[-.]\\d{4}")  » являются необязательными. Так что, если он пустой, это тоже нормально.
» являются необязательными. Так что, если он пустой, это тоже нормально. ].
]. » и «_». Все они могут быть упакованы так:
» и «_». Все они могут быть упакованы так: com"[[2]]
com"[[2]]  net",
net",  ‘\\w’ обозначает символ слова, который может включать строчные буквы, прописные буквы и цифры. Знак «+» указывает на то, что таких символов может быть один или несколько.
‘\\w’ обозначает символ слова, который может включать строчные буквы, прописные буквы и цифры. Знак «+» указывает на то, что таких символов может быть один или несколько. com или ‘.net’. Это можно указать явно.
com или ‘.net’. Это можно указать явно.
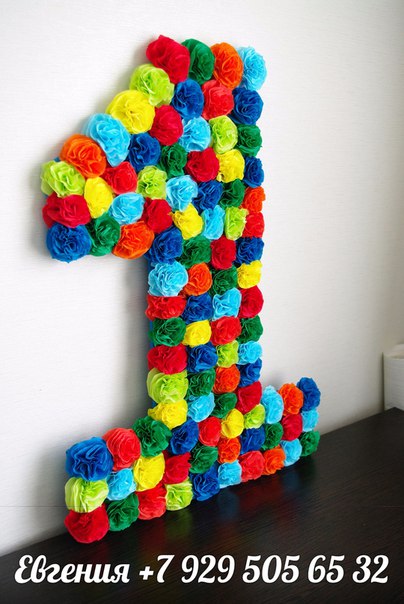
 [3-7]* будет соответствовать 0 или более последовательным цифрам в диапазоне от 3 до 7.
[3-7]{3} будет соответствовать 3 последовательным цифрам в диапазоне от 3 до 7.
[3-7]{3,6} будет соответствовать от 3 до 6 последовательных цифр в диапазоне от 3 до 7.
[3-7]{3,} будет соответствовать 3 или более последовательным цифрам в диапазоне от 3 до 7.
[3-7]* будет соответствовать 0 или более последовательным цифрам в диапазоне от 3 до 7.
[3-7]{3} будет соответствовать 3 последовательным цифрам в диапазоне от 3 до 7.
[3-7]{3,6} будет соответствовать от 3 до 6 последовательных цифр в диапазоне от 3 до 7.
[3-7]{3,} будет соответствовать 3 или более последовательным цифрам в диапазоне от 3 до 7.


 Политика конфиденциальности.
Политика конфиденциальности. Дополнительные сведения см. в разделе Экранирование символов.
Дополнительные сведения см. в разделе Экранирование символов. "
" 










 Это может значительно улучшить производительность, когда квантификаторы встречаются в атомарной группе или в остальной части шаблона.
Это может значительно улучшить производительность, когда квантификаторы встречаются в атомарной группе или в остальной части шаблона.


 Соответствует значению нумерованного подвыражения.
Соответствует значению нумерованного подвыражения.
 jpg\""
jpg\"" 

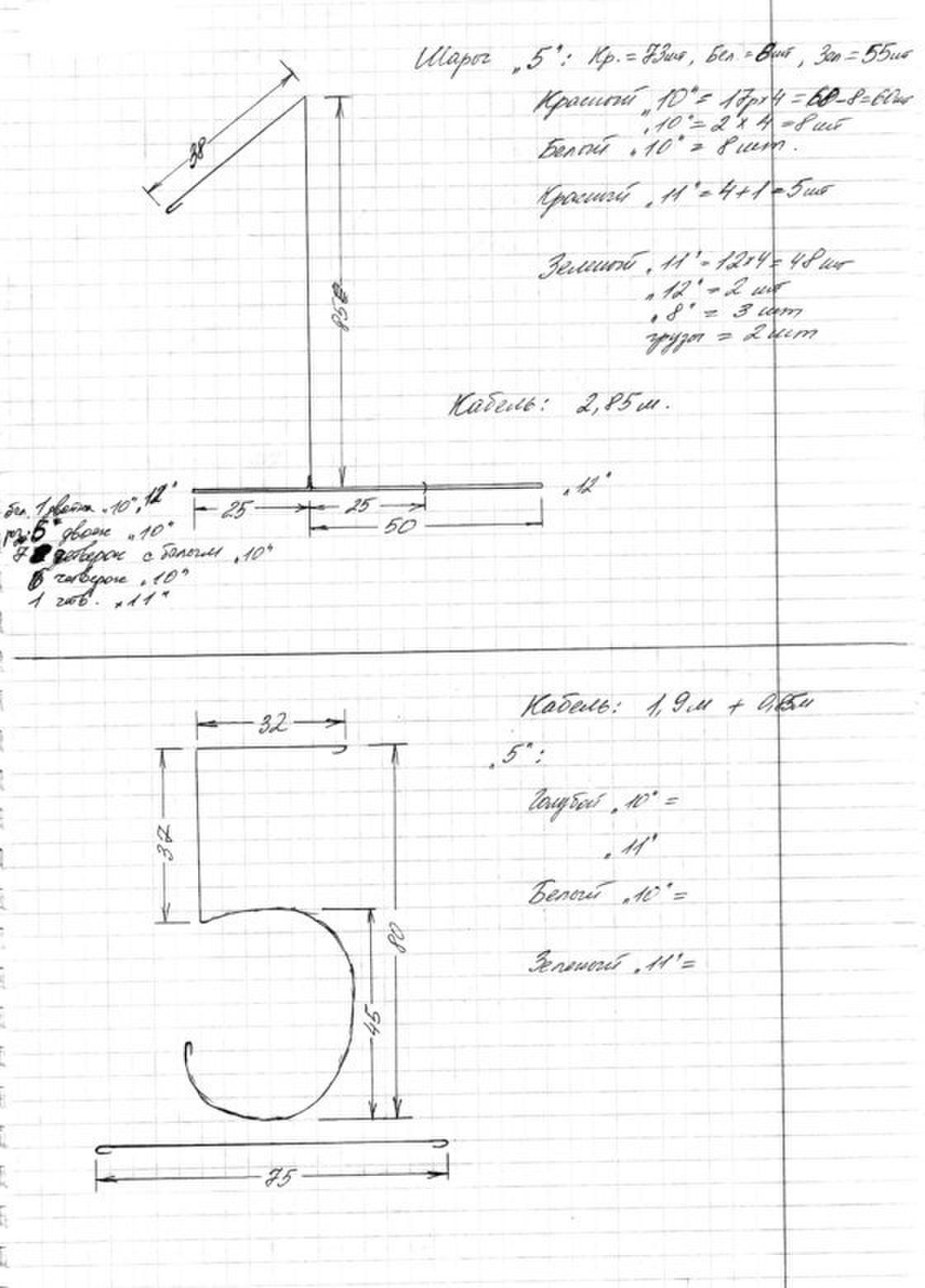 Параметр применяется к шаблону регулярного выражения, начиная с точки, в которой он определен, и действует либо до конца шаблона, либо до точки, где другая конструкция обращает параметр.
Параметр применяется к шаблону регулярного выражения, начиная с точки, в которой он определен, и действует либо до конца шаблона, либо до точки, где другая конструкция обращает параметр.
 Дополнительные сведения см. в разделе Параметры регулярных выражений.
Дополнительные сведения см. в разделе Параметры регулярных выражений. Например,
Например,  Эквивалентно
Эквивалентно  \f\n\r\t\v\u00a0\u1680\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff] . Например,
\f\n\r\t\v\u00a0\u1680\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff] . Например,  Например,
Например,  Он ведет себя одним из двух способов.
Он ведет себя одним из двух способов.

 \d{3}[.-]?)?\d{3}[.-]?\d{4}$
\d{3}[.-]?)?\d{3}[.-]?\d{4}$  Эти
кодовые точки отображаются в виде U+0000 .U+002E, для
например, представляет кодовую точку для точки или точки (.).
Эти
кодовые точки отображаются в виде U+0000 .U+002E, для
например, представляет кодовую точку для точки или точки (.). Размещение этих заметок в конце
глав помогает поддерживать поток основного текста в движении вперед
вместо того, чтобы останавливаться, чтобы обсудить каждую деталь по пути.
Размещение этих заметок в конце
глав помогает поддерживать поток основного текста в движении вперед
вместо того, чтобы останавливаться, чтобы обсудить каждую деталь по пути. книга, но, увы, не в печати. Итак, если вы читаете эту книгу на бумаге,
тогда, когда я упомяну цвет, ваш мир будет в оттенках серого, с моим
извинения.
книга, но, увы, не в печати. Итак, если вы читаете эту книгу на бумаге,
тогда, когда я упомяну цвет, ваш мир будет в оттенках серого, с моим
извинения. Что за
регулярное выражение
Что за
регулярное выражение  Есть лучший способ с
нечто, называемое стенографией.
Есть лучший способ с
нечто, называемое стенографией.

 Не волнуйтесь, если вы не полностью
поймите это прямо сейчас. Позже вы увидите множество примеров групп.
в книге.
Не волнуйтесь, если вы не полностью
поймите это прямо сейчас. Позже вы увидите множество примеров групп.
в книге. Есть и другие квантификаторы, такие как знак плюс (
Есть и другие квантификаторы, такие как знак плюс (
 (знак знака вставки) в начале регулярного выражения или после
вертикальная черта (
(знак знака вставки) в начале регулярного выражения или после
вертикальная черта ( 
Это окончательное регулярное выражение соответствует 10-значному североамериканскому номер телефона, со скобками, дефисами или точками или без них.Пытаться различные формы числа, чтобы увидеть, что будет соответствовать (и что не будет).
Примечание
Группа захвата в приведенном выше регулярном выражении не
необходимый. Группа нужна, а захватывающая часть - нет. Там
это лучший способ сделать это: группа без захвата. Когда мы вернемся к этому
регулярное выражение в последней главе книги, вы поймете
Зачем.:max_bytes(150000):strip_icc()/NUMBERS-04-56a80f0d3df78cf7729bc1ea.png)
В заключение этой главы я покажу вам регулярное выражение для номер телефона в нескольких приложениях.
TextMate — это редактор, доступный только на Mac и использующий тот же библиотека регулярных выражений в качестве языка программирования Ruby. Ты можешь использовать регулярные выражения с помощью функции поиска (поиска), как показано на рис. 1–3. Установите флажок рядом с Обычный выражение .
Рис. 1-3. Регулярное выражение номера телефона в TextMate
Notepad++ доступно в Windows и является популярным бесплатным редактором, использующим библиотека регулярных выражений PCRE. Вы можете получить к ним доступ через поиск и замените (Рисунок 1-4), нажав переключатель рядом to Регулярное выражение .
Рис. 1-4. Регулярное выражение номера телефона в Notepad++
Oxygen также является популярным и мощным XML-редактором, использующим регулярные выражения Perl 5.
синтаксис. Вы можете получить доступ к регулярным выражениям через поиск и замену
диалоговое окно, как показано на рис. 1-5, или через его обычное
построитель выражений для схемы XML. Чтобы использовать регулярные выражения с
Найти/Заменить, поставить галочку рядом с Обычный
выражение .
1-5, или через его обычное
построитель выражений для схемы XML. Чтобы использовать регулярные выражения с
Найти/Заменить, поставить галочку рядом с Обычный
выражение .
Рис. 1-5. Регулярное выражение номера телефона в Oxygen
На этом введение заканчивается.Поздравляем. Вы рассмотрели много земли в этой главе. В следующей главе мы сосредоточимся на простое сопоставление с образцом.
 regexpal.com) является
веб-реализация регулярных выражений на основе JavaScript. Его
не самая полная реализация, да и не все умеет
что могут делать регулярные выражения; тем не менее, это чистый, простой и
очень простой в использовании инструмент обучения, и он предоставляет множество функций для
вы, чтобы начать.
regexpal.com) является
веб-реализация регулярных выражений на основе JavaScript. Его
не самая полная реализация, да и не все умеет
что могут делать регулярные выражения; тем не менее, это чистый, простой и
очень простой в использовании инструмент обучения, и он предоставляет множество функций для
вы, чтобы начать. :max_bytes(150000):strip_icc()/NUMBERS-10-56a80f0e5f9b58b7d0f045f6.png) Как только вы изучите
различные части регулярных выражений, которые вы будете использовать в своих
способность сопоставлять строки любого типа.
Как только вы изучите
различные части регулярных выражений, которые вы будете использовать в своих
способность сопоставлять строки любого типа.  а...s$'
test_string = 'бездна'
результат = re.match (шаблон, тестовая_строка)
если результат:
print("Поиск успешен.")
еще:
print("Поиск не удался.")
а...s$'
test_string = 'бездна'
результат = re.match (шаблон, тестовая_строка)
если результат:
print("Поиск успешен.")
еще:
print("Поиск не удался.")
 используется для проверки того, начинается ли строка с определенного символа.аб
используется для проверки того, начинается ли строка с определенного символа.аб 

 Это регулярное выражение
Это регулярное выражение  Например,
Например, 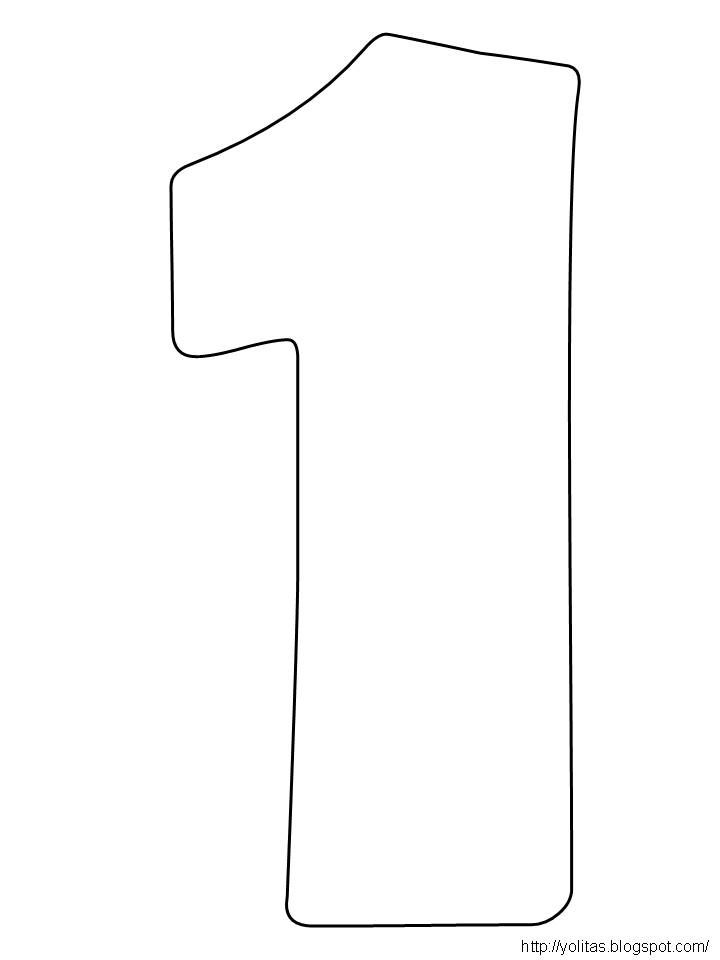 Здесь
Здесь 
 0-9]
0-9] 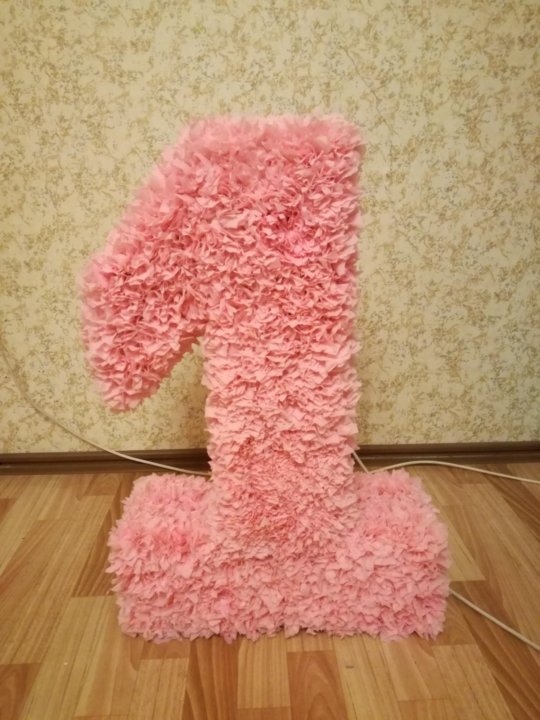 \t\n\r\f\v] .
\t\n\r\f\v] . a-zA-Z0-9_]
a-zA-Z0-9_] 
 Привет 34'
шаблон = '\d+'
результат = re.findall (шаблон, строка)
печать (результат)
# Вывод: ['12', '89', '34']
Привет 34'
шаблон = '\d+'
результат = re.findall (шаблон, строка)
печать (результат)
# Вывод: ['12', '89', '34']
 '
шаблон = '\d+'
# макссплит = 1
# разбить только при первом вхождении
результат = re.split (шаблон, строка, 1)
печать (результат)
# Вывод: ['Двенадцать:', ' Восемьдесят девять:89 Девять:9.']
'
шаблон = '\d+'
# макссплит = 1
# разбить только при первом вхождении
результат = re.split (шаблон, строка, 1)
печать (результат)
# Вывод: ['Двенадцать:', ' Восемьдесят девять:89 Девять:9.']

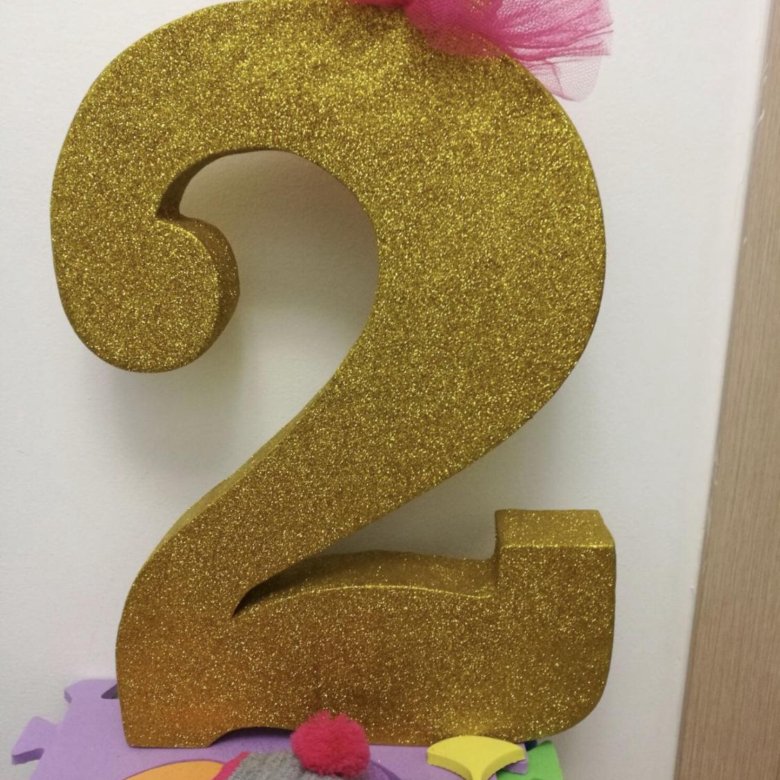 search()
search() 


 С использованием
функцию BLANKS( ) в new_string, а не
чем буквенный пробел, делает пробелы более легкими для чтения и менее вероятными
игнорировать:
С использованием
функцию BLANKS( ) в new_string, а не
чем буквенный пробел, делает пробелы более легкими для чтения и менее вероятными
игнорировать: ]*\d{3}[\s- \.]*\d{4})(.*)", "$2")
]*\d{3}[\s- \.]*\d{4})(.*)", "$2")  в именах.Учет вариаций в данных об именах обычно требует больше
сложные регулярные выражения, чем в приведенном выше примере.
в именах.Учет вариаций в данных об именах обычно требует больше
сложные регулярные выражения, чем в приведенном выше примере.

 Примеры
ниже показано усечение:
Примеры
ниже показано усечение: для увеличения длины поля, как показано во втором примере ниже.
для увеличения длины поля, как показано во втором примере ниже. Многочисленные ресурсы, объясняющие регулярные выражения
доступны в Интернете.
Многочисленные ресурсы, объясняющие регулярные выражения
доступны в Интернете.
 Вы можете указать точное число, диапазон или открытый диапазон.
Вы можете указать точное число, диапазон или открытый диапазон.
:max_bytes(150000):strip_icc()/NUMBERS-03-56a80f0c5f9b58b7d0f045db.png) $ . * + ? знак равно : | \ ( ) [ ] { }
$ . * + ? знак равно : | \ ( ) [ ] { }  Этот метасимвол
может использоваться в параметре шаблона в обоих
REGEXFIND() и REGEXREPLACE().
Этот метасимвол
может использоваться в параметре шаблона в обоих
REGEXFIND() и REGEXREPLACE(). интервал
целое число, определяющее порядковую позицию группы
в целевой строке по отношению к любым другим группам. Этот метасимвол
может использоваться только в параметре new_string
в REGEXREPLACE().
интервал
целое число, определяющее порядковую позицию группы
в целевой строке по отношению к любым другим группам. Этот метасимвол
может использоваться только в параметре new_string
в REGEXREPLACE(). Например:
Например: отрицает содержимое
отрицает содержимое